How to Build Data Pipelines That Actually Work
A practical guide on how to build data pipelines. Learn to design, deploy, and maintain robust systems with real-world advice on tools and architecture.

Before you touch any code or spin up a server, you have to start with a solid plan. Building a data pipeline is all about defining your business goals, identifying data sources, choosing the right architecture like ETL or ELT, and picking the best tools to get the data flowing automatically. Skipping the blueprint phase is a recipe for disaster; you’ll end up with a brittle system that costs a fortune to maintain and doesn't actually help anyone.
Designing Your Data Pipeline Blueprint
Think of this design phase as drawing up the architectural plans for a house. You wouldn't just start nailing boards together, right? This is where you separate a fragile, high-maintenance pipeline from a resilient system that genuinely solves business problems.
The whole process kicks off by talking to the people who will actually use the data. Your job isn't just to collect a list of requirements; it's to dig deep and translate their business objectives into specific data needs. What questions are they really trying to answer? What decisions are hanging in the balance? This conversation is everything because it sets the purpose for the entire pipeline.
Identify Your Data Sources and Destinations
Once you've nailed down the "why," you can get to the "what" and "where." Data is almost never in one neat, tidy location. You'll need to map out every single source your pipeline will need to connect with.
Common sources usually include a mix of:
- Relational Databases: Think PostgreSQL or MySQL, where your core application data lives.
- Third-Party APIs: For pulling data from tools like Salesforce, Zendesk, or your marketing platforms.
- Event Streams: Real-time data from user activity, often captured with tools like Kafka or Segment.
- Flat Files: Don't forget the humble CSV or log files, which often come from legacy systems and live in cloud storage.
At the same time, you have to know exactly where this data is going. Is it destined for a cloud data warehouse like Snowflake or BigQuery for deep analysis? Or maybe it needs to power a live dashboard or be fed into a machine learning model. The destination has a massive impact on every other choice you make.
Estimate Data Volume and Velocity
You absolutely have to get a handle on the scale of your data. It boils down to two critical questions: how much data are you moving (volume), and how fast is it coming in (velocity)? A pipeline that moves a few gigabytes in a daily batch has completely different requirements than one that needs to process terabytes of streaming data every hour.
Getting this estimate right informs everything from the tools you select to your final cloud bill. If you underestimate, the system will crash. If you overestimate, you're just burning money.
The demand for solutions that can handle this scale is exploding. The global market for data pipeline tools was valued at around USD 5.75 billion in 2023 and is expected to rocket to nearly USD 18.9 billion by 2033. This growth is fueled by predictions that global data volumes will hit an incredible 175 zettabytes by 2025. You can dig into these trends in this Data Horizzon Research report.
By creating a detailed blueprint first, you're building a clear roadmap that connects your technical work to real business goals. This makes sure every piece of the pipeline has a purpose, transforming raw data into something truly valuable. To see how this planning fits into a bigger picture, take a look at our guide on implementing enterprise data analytics.
Choosing the Right Tools and Architecture
Once you have a solid blueprint for your data pipeline, it’s time to get into the nuts and bolts: the technology. This is where you pick the architectural pattern and the specific tools that will bring your plan to life. Making the right call here is crucial. It’s the difference between a pipeline that scales with your business and one that requires a costly rebuild down the road.
Your first big decision is the architectural pattern. This isn't just some abstract technical choice; it dictates how your data moves and when it becomes valuable for analysis. Think of it as the foundation of your entire data operation.
I always recommend starting with a whiteboard session. Sketching out the flow and getting the whole team aligned on a visual plan is an incredibly valuable first step.
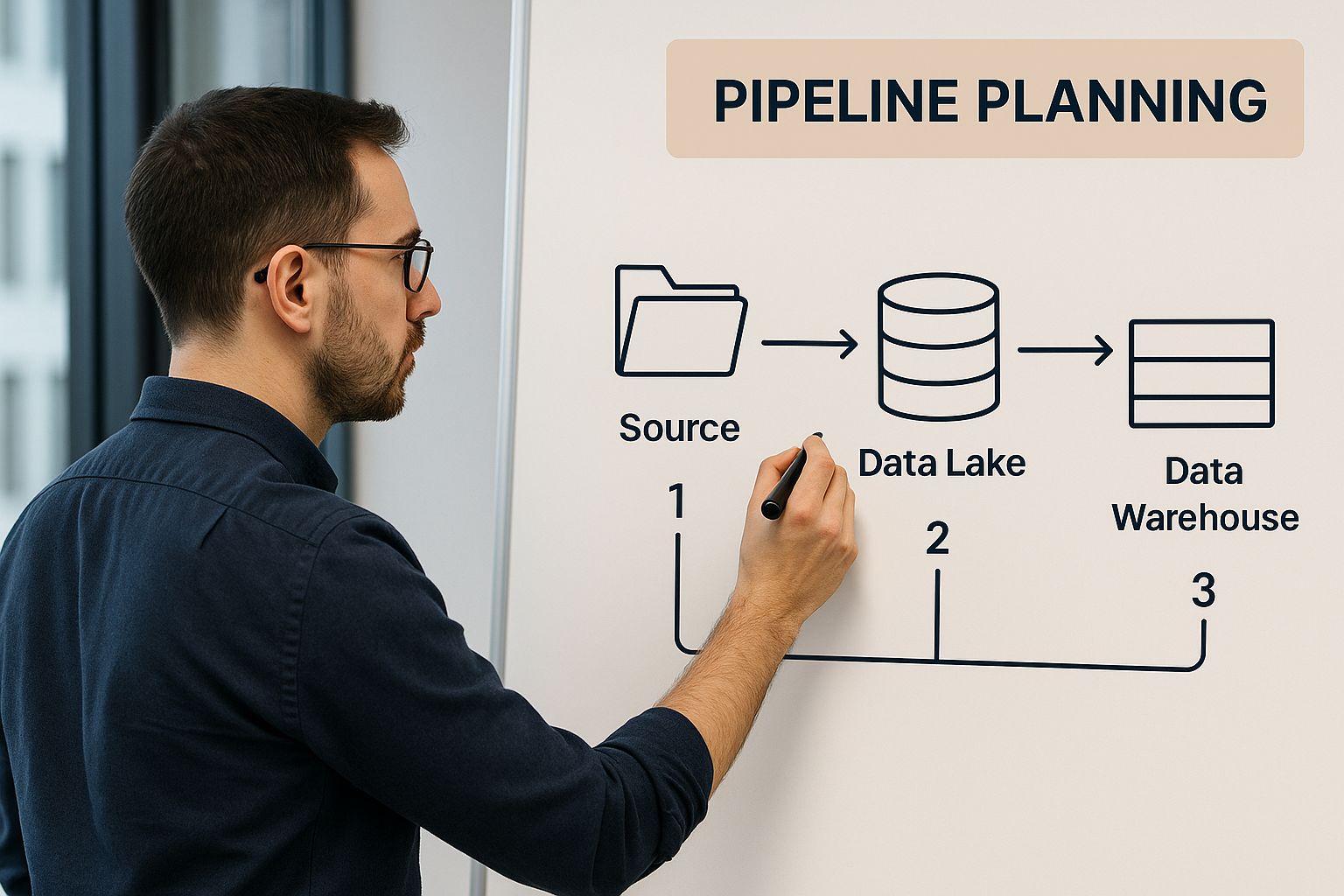
This simple exercise ensures that every technical choice you make from here on out is directly tied to a business goal, which helps prevent a lot of headaches later on.
ETL vs. ELT vs. Streaming: What's the Right Fit?
There are three primary patterns for building data pipelines: ETL, ELT, and real-time streaming. Each has its own strengths and is suited for different scenarios.
- ETL (Extract, Transform, Load): The traditional workhorse. In this model, you extract data, clean and reshape it on a separate processing server, and only then load the pristine, structured data into your warehouse. It's a great fit for situations where transformations are complex or you're dealing with sensitive data that needs to be scrubbed before it lands in your database.
- ELT (Extract, Load, Transform): The modern, cloud-first approach. Here, you dump raw data directly into a powerful data warehouse like Snowflake or Google BigQuery. All the transformation happens inside the warehouse, taking advantage of its massive parallel processing power. This gives you incredible flexibility, especially when dealing with huge volumes of semi-structured data.
- Streaming: This is for when you need answers now. Instead of processing data in batches, a streaming architecture handles it continuously as it arrives, often with just milliseconds of delay. It's essential for things like real-time fraud detection, live dashboards, or monitoring IoT devices.
To help you decide, here’s a quick comparison of the three main architectural patterns. This table breaks down their core characteristics, common use cases, and some of the tools you might encounter for each.
Comparison of Data Pipeline Architecture Patterns
| Pattern | Transformation Stage | Primary Use Case | Example Tools |
|---|---|---|---|
| ETL | Before loading to the warehouse | Structured data, complex business rules, data privacy compliance | Informatica PowerCenter, Talend, AWS Glue |
| ELT | After loading into the warehouse | Big data analytics, data lakes, flexible data exploration | Fivetran, dbt, Stitch, Snowflake, BigQuery |
| Streaming | In-flight, as data is generated | Real-time analytics, fraud detection, IoT data processing | Apache Kafka, Amazon Kinesis, Google Cloud Pub/Sub |
Choosing the right pattern really depends on your specific needs—from the type of data you're working with to how quickly you need insights. Once you've settled on an approach, you can start building your toolkit.
Assembling Your Toolkit
With an architecture in mind, the next step is picking the tools. You'll generally find yourself choosing between two main camps: open-source software or fully managed cloud services.
An open-source tool like Apache Airflow offers amazing control and a huge, active community. It lets you define your entire pipeline as code, which is fantastic for version control and complex workflows. However, this power comes with the responsibility of managing the underlying infrastructure yourself. It’s a great choice for experienced engineering teams who want to avoid vendor lock-in and need that granular control.
On the other side, you have managed cloud services from providers like Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP). These platforms offer services like AWS Glue and Google Cloud Dataflow that handle all the infrastructure, scaling, and maintenance for you.
This means your team can focus entirely on building pipeline logic instead of worrying about servers. By 2025, most enterprises will be leaning heavily on these cloud-native tools. The trade-off is usually a bit less flexibility and potentially higher costs at scale.
This approach is perfect for teams that need to move fast and want to minimize their operational burden. The insights from these pipelines often feed into a product intelligence platform, helping teams make smarter, data-driven decisions about their products.
Ultimately, there’s no single "best" tool. The right choice is a strategic balance of control, cost, scalability, and the skills you have on your team.
Bringing Your Data Pipeline to Life: Ingestion and Transformation
With your architecture mapped out and your tools selected, it’s time to roll up your sleeves and start building. This is where the diagrams and plans become a living, breathing system. We’re going to tackle the two most critical parts of any data pipeline: getting the data in (ingestion) and making it useful (transformation).
The goal here is more than just writing code that runs without errors. We're building a system that's modular, easy to test, and won't give you a headache to maintain six months from now. Think of it like a well-designed electrical system in a house. You don't just run one giant wire; you install separate circuits with breakers so you can isolate problems without shutting everything down.

Nailing Data Ingestion From Any Source
Data ingestion is the front door to your entire pipeline. If you can't get data in the door reliably, nothing else you build downstream matters. The real challenge is that data is scattered everywhere—in different formats, systems, and vendors, each with its own quirks. A solid ingestion strategy has to be flexible enough to handle this mess.
Most of the time, your ingestion work will fall into one of three buckets:
- Pulling from Databases (Batch Extraction): This is your classic scenario, especially when dealing with production databases or older legacy systems. You’ll typically set up a scheduled job—often running nightly—that queries for any records that have been added or changed since the last run. The key here is incremental loading. Never, ever pull the entire database every day. It's wildly inefficient and puts a ton of stress on the source system.
- Connecting to Third-Party APIs: Need data from Salesforce, Google Analytics, or Stripe? You'll be working with their APIs. This means writing code that can gracefully handle authentication (like OAuth tokens), respect rate limits (to avoid getting blocked), and manage pagination (fetching large result sets page by page). Good error handling and a smart retry mechanism are non-negotiable here.
- Handling Real-Time Event Streams: For things like website clickstreams, IoT sensor data, or application logs, you'll be tapping into a constant flow of events from a source like Apache Kafka or AWS Kinesis. Your ingestion service acts as a "consumer," listening for new messages, grouping them into small batches, and landing them in your data lake or warehouse. It's all about managing a continuous flow, not just a single pull.
The Art of Data Transformation
Once the raw data is safely inside your system, the real work begins. It’s almost never in the right shape for analysis. This is where transformation comes in—the process of cleaning, structuring, and enriching that raw data. This is, without a doubt, the most complex and most important part of the entire pipeline.
Transformation is where you apply your business logic to turn messy, raw inputs into a trusted, valuable asset. If you skimp on this step, you're just creating a fast track to the classic "garbage in, garbage out" problem.
You'll spend most of your time on tasks like these:
- Cleaning and Standardizing: This is the foundational work. You'll handle
NULLvalues, correct data types (like turning a "2023-10-26" string into a proper date), and enforce consistency (like making sure all country codes follow the ISO standard). - Joining and Enriching: Rarely does a single data source tell the whole story. You'll constantly be combining datasets. A great example is joining sales transaction data from your e-commerce platform with customer profiles from your CRM to analyze spending habits.
- Aggregating: This means summarizing raw data into a more useful format. Think about rolling up thousands of individual order line items into a clean
daily_sales_by_producttable.
Writing Code You Won't Hate Later
The single biggest mistake I see engineers make is writing their entire transformation logic in one giant, thousand-line SQL script. It’s a nightmare to debug and impossible to update. The right way is to break your logic into small, single-purpose, and reusable models.
If you’re using a modern tool like dbt (data build tool), you can structure your project to make this easy:
- Staging Models: Create one "staging" model for each raw source table. Their only job is light cleaning—renaming columns, casting data types, and basic standardization.
- Intermediate Models: This is where you start combining things. You might build an intermediate model that joins your
stg_usersandstg_orderstables to create a unified view of customer activity. - Final Data Marts: These are the polished, final tables that power your dashboards and reports. They are aggregated, clean, and built for business users. A table like
fct_monthly_revenuewould be a final mart.
This layered approach makes your pipeline incredibly transparent. You can test each piece in isolation and easily trace data lineage back to the source if something looks off. Structuring your project this way is a cornerstone of customer data integration best practices, ensuring the data you deliver is something the business can actually trust.
Ultimately, by focusing on robust ingestion and clean, modular transformation, you’re not just shuffling data around. You’re building a reliable factory that consistently produces high-quality, analysis-ready data—the fuel for every data-driven decision in your organization.
Making Your Pipeline Resilient and Trustworthy
A data pipeline that runs perfectly on your laptop can fall apart in the chaos of a real production environment. Even worse is the pipeline that fails silently, quietly feeding bad data into your analytics and slowly eroding everyone's trust in the numbers. Building a resilient, trustworthy pipeline isn't something you bolt on at the end; it has to be baked in from the very beginning.
This shift from just moving data to moving data reliably is why the market for data pipeline tools is exploding. It was valued at around 12.1 billion in 2024 and is on track to hit a staggering ****48.3 billion by 2030. That massive investment is all about getting tools that guarantee data quality and keep latency low, turning fragile scripts into dependable business assets. You can dig deeper into these trends in this Grand View Research analysis.
Implement Strategic Monitoring and Logging
You can't fix what you can't see. The cornerstone of a resilient system is solid monitoring and logging that gives you a clear window into what’s happening at every single stage. This isn’t just about catching errors—it’s about creating an audit trail that lets you debug problems fast.
At a minimum, your logs need to capture the essentials for every pipeline run:
- Run Start and End Times: The most basic but critical metric for tracking performance.
- Records Processed: How many rows did you read? How many did you write? A sudden drop to zero is a classic sign that something’s broken upstream.
- Status (Success/Failure): Did the job actually complete? If not, what was the error that stopped it?
- Key Metadata: Always include identifiers like a job ID or run date. You'll thank yourself later when you're trying to filter through thousands of log entries.
Once you’re logging this information, you need to automate the alerting. Nobody has time to stare at a dashboard all day. Set up alerts that fire when a job fails, runs way longer than usual, or processes a suspiciously low number of records. This way, you find out about problems the moment they happen, not when a frustrated analyst pings you about a broken dashboard.
Proactively Validate Your Data Quality
Bad data will always try to find a way into your pipeline. Your job is to build a strong defense against it. Proactive data quality validation is about catching issues at the door before they contaminate your entire data warehouse and lead to terrible business decisions.
Start with the basics and layer on more sophisticated checks over time:
- Schema Validation: This is your first and most powerful line of defense. Does the incoming data match the columns and data types you expect? If a source API suddenly changes a column from an integer to a string, your pipeline needs to stop dead in its tracks.
- Null and Uniqueness Checks: Identify the columns that can never be empty (like a
user_id) or must be unique (like anorder_id). The job should fail immediately if these fundamental rules are broken. - Freshness Checks: Is the data actually recent? If your daily pipeline hasn't received new data in three days, that's a massive red flag pointing to an upstream problem.
- Distributional Checks: For more advanced pipelines, you can start looking for weird shifts in the data itself. For example, if the average
transaction_amountsuddenly spikes by 500%, it might be a data entry bug or an issue with the source system.
Design for Failure with Smart Error Handling
Let's be clear: your pipelines will fail. It’s not a question of if, but when. A third-party API will go down, a network connection will drop, or a database will temporarily lock up. A truly resilient pipeline is designed with this reality in mind. Instead of just crashing and burning, it knows how to handle temporary hiccups gracefully.
This is where intelligent retries become your best friend. So many production failures are transient—a brief network blip or a momentary API outage. Implementing an exponential backoff strategy can automatically solve a huge chunk of these issues.
Here’s a practical way to set it up:
- Immediate Retry: On the first failure, try again after a short delay, like 1 minute.
- Exponential Backoff: If it fails again, double the wait time with each attempt—2 minutes, then 4, then 8.
- Set a Hard Limit: After 3-5 failed retries, kill the job and send a high-priority alert to a human. This prevents a broken job from running in a loop forever, hogging resources.
This simple strategy makes your pipeline tough. It can power through temporary glitches without you having to do anything, saving you from getting paged at 3 AM for a problem that would have fixed itself in five minutes. By combining smart monitoring, proactive validation, and intelligent error handling, you can transform a fragile script into a production-grade asset the business can actually depend on.
Deploying and Automating Your Pipeline

A data pipeline that only runs when you hit "play" on your laptop isn't really a pipeline—it's just a script. The real magic happens when you transition from a manual process to a fully automated, production-grade system. This is the final and most critical phase: giving your pipeline a schedule and the intelligence to run itself, delivering data reliably without you having to think about it.
The core of this automation is an orchestration tool. This is the system that triggers your pipeline, manages the sequence of tasks, and handles retries when, inevitably, something goes wrong. Trust me, just using a simple cron job might seem easy at first, but it's a surefire path to silent failures and a maintenance nightmare down the road.
Choosing Your Orchestration Engine
The orchestration tool you pick will be the backbone of your entire automation strategy, so it’s a big decision.
For teams who live and breathe code and want maximum control, open-source tools like Apache Airflow are the industry gold standard. Airflow lets you define incredibly complex workflows (called DAGs) using Python, which gives you immense power to manage tricky dependencies and custom logic.
On the other hand, if your infrastructure is already heavily invested in a specific cloud provider, their native services are often the path of least resistance. They offer seamless integration that can save you a ton of setup time.
- AWS Step Functions: This is a fantastic choice for orchestrating serverless functions and other AWS services. Its visual workflow builder makes it easy to see what's happening.
- Google Cloud Composer: Think of this as Apache Airflow, but managed by Google. You get all the power of Airflow without the headache of managing the underlying servers.
- Azure Data Factory: A very comprehensive, GUI-driven service that's perfect for building and scheduling ETL and ELT workflows if you're all-in on the Azure ecosystem.
Ultimately, the right tool comes down to your team's skills, your existing cloud setup, and just how complex your pipeline's dependencies are.
Automation is so much more than just scheduling a job. It's about building a predictable, repeatable process that eliminates human error and creates genuine trust in the data your pipeline produces.
Adopting CI/CD for Data Pipelines
In the software world, no one pushes code to production without it being automatically tested and deployed. This practice, known as Continuous Integration and Continuous Deployment (CI/CD), is just as crucial for data pipelines. It’s what allows you to make changes with confidence, knowing you aren't about to break a business-critical data flow.
A solid, basic CI/CD workflow for a data pipeline looks something like this:
- A developer pushes a code change to the pipeline's repository (like on GitHub).
- A CI server automatically kicks off a series of tests. Critically, this must include data quality checks against a staging dataset to ensure your logic changes haven't created unexpected issues.
- If—and only if—all the tests pass, the new pipeline code is automatically deployed to the production environment.
This feedback loop ensures every single change is validated before it ever touches live data. It transforms deployments from a high-stress, all-hands-on-deck event into a routine, low-risk process.
Your Pre-Deployment Checklist
Before you set your pipeline loose into the wild, a final "pre-flight" check is absolutely essential. I've seen too many teams rush this step and then spend hours firefighting easily preventable problems.
Run through this list before any major deployment:
- Permissions and Access: Does the pipeline's service account have the exact permissions it needs—and nothing more? Over-permissioning is a huge security risk.
- Dependency Management: Are all your libraries and packages (e.g., in a
requirements.txtfile or a Docker image) locked to specific versions? This prevents surprises when a dependency updates. - Environment Variables: Have you moved all secrets, API keys, and credentials out of your code and into a secure vault or secrets manager?
- Alerting Configuration: Are your failure alerts actually configured? And more importantly, are they routed to a person or a channel that is actively monitored?
Spending thirty minutes to meticulously go through this checklist will save you hours of painful debugging later. It’s the final step in building a pipeline that is not just functional, but truly reliable, secure, and ready to become a trusted asset for your organization.
Common Questions About Building Data Pipelines
As you get your hands dirty building data pipelines, you're going to hit some roadblocks. It's just part of the job. But knowing the common questions and having solid answers ready can save you from a world of late-night debugging and frustrating rework.
Let's walk through some of the most frequent questions I see pop up time and time again.
What Is the Main Difference Between ETL and ELT?
The big difference between ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) comes down to a single, critical question: Where does the data transformation happen? It sounds like a minor detail, but your answer has a massive ripple effect on your architecture, costs, and how flexible your system will be down the road.
With the old-school ETL approach, you pull data from a source, clean it up and reshape it on a separate processing server, and only then do you load that clean, structured data into your warehouse.
ELT flips that script. You extract the raw, untouched data and dump it straight into a powerful cloud data warehouse like Snowflake or Google BigQuery. All the heavy lifting—the transformations, the cleaning, the modeling—happens right inside the warehouse itself, using its massive parallel processing power. For most modern data stacks dealing with huge, messy datasets, ELT is the way to go because it's faster and far more adaptable.
How Do I Choose the Right Orchestration Tool?
Picking the right orchestration tool isn't about finding the "best" one, but the best one for your team. The decision really hinges on your existing tech stack and how complicated your workflows are.
If you're all-in on a single cloud, sticking with their native tools is often the path of least resistance. AWS Step Functions or Google Cloud Composer are built to play nicely within their ecosystems, which can make setup a breeze.
But if you're dealing with complex, interdependent jobs and your team lives and breathes code, Apache Airflow is still the king. It gives you incredible control and flexibility. On the other hand, don't over-engineer it. For simple, recurring tasks, a good old cron job or a scheduled serverless function might be all you really need. Always think about the learning curve and what kind of monitoring you'll need before you commit.
Think of your orchestrator as the brain of your entire data operation. You need to pick one that not only solves today's problems but can also handle the complexity you'll inevitably face a year from now.
What Are the Most Common Pipeline Challenges to Anticipate?
Every data engineer earns their stripes fighting the same battles. If you know what they are ahead of time, you can build defenses right into your pipelines from the start.
Sooner or later, you're going to run into these four horsemen of data pipeline apocalypse:
- Evolving Source Data: APIs get updated, someone renames a column, or a schema just drifts over time. It happens without warning and will absolutely break your pipeline.
- Poor Data Quality: Let's be honest, source data is often a mess. It's incomplete, inconsistent, or just plain wrong. Without strong validation checks, you'll be stuck cleaning up garbage data downstream instead of building cool new things.
- Scalability Issues: That pipeline you built to handle a few gigabytes of data will fall over when it suddenly has to process a few terabytes. You have to design for future scale, or you'll be forced into a painful, high-pressure rebuild when you least expect it.
- Silent Failures: This is the most dangerous problem of all. A pipeline that breaks without telling anyone is a nightmare. It can be pumping bad data into your systems for days, completely eroding trust with your stakeholders.
SigOS helps you build better products by turning qualitative customer feedback into quantifiable, revenue-driving insights. Instead of guessing what to build next, our AI-driven platform identifies the bugs and feature requests that have the biggest impact on churn and expansion. Transform your support tickets, sales calls, and usage data into a clear, prioritized roadmap. Learn how SigOS connects product decisions to revenue outcomes.
Keep Reading
More insights from our blog


Ready to find your hidden revenue leaks?
Start analyzing your customer feedback and discover insights that drive revenue.
Start Free Trial →