Hightouch Reverse ETL: The Practical Explainer
A deep, practical guide to Hightouch Reverse ETL. Learn its architecture, use cases, implementation, and how it powers platforms like SigOS for data activation.

You already know who is likely to churn. You've probably got a dashboard that flags weak onboarding, stalled accounts, and features tied to expansion. The problem is that the insight lives in the warehouse and the action lives somewhere else.
That gap frustrates product teams more than most data problems. A product manager sees a decline in adoption for a core workflow. Support sees a spike in related tickets. Sales hears the same objection in renewal calls. Analytics can connect the dots, but if nobody can push that signal into Salesforce, Zendesk, Jira, Braze, or Slack fast enough, the company still reacts late.
That's where hightouch reverse etl becomes useful. Not as a flashy category label, but as the missing operational layer between trusted warehouse models and the tools teams work in every day.
Most articles stop at lead scoring and audience syncs. Those are valid use cases, but they undersell the bigger shift. Reverse ETL also changes how product organizations work. It lets warehouse insights shape roadmap decisions, escalation paths, and customer follow-up in a continuous loop instead of a quarterly review deck.
Why Your Data Warehouse Is a Goldmine You Can't Spend
A familiar pattern shows up in growing SaaS companies.
The data team builds a strong model for customer health. Product usage is clean. Billing data is joined. Support volume is incorporated. The dashboard is accurate enough that everyone trusts it. Then nothing happens until a renewal call goes sideways or a frustrated customer opens another ticket.

The issue usually isn't analysis quality. It's execution speed.
The warehouse knows, but the workflow doesn't
I've seen teams identify churn risk correctly and still fail to intervene because the signal stayed in Looker, Tableau, or a warehouse table that only analysts touched. Meanwhile:
- Customer success teams worked from stale CRM fields.
- Support agents handled tickets without product context.
- Product managers reviewed patterns after the damage was already visible in retention.
- Growth teams kept sending campaigns based on broad segments instead of recent behavior.
The warehouse had the answer. The business systems didn't.
Practical rule: If the insight changes what a team should do today, it belongs in the tool where that team already works.
That's the core business case for reverse ETL. It makes warehouse data operational. Instead of asking people to check one more dashboard, it moves the model output into the system that drives the next action.
Why this matters for product teams
Sales and marketing were the first obvious beneficiaries. Sync lead scores into Salesforce. Push audiences into ad platforms. Trigger lifecycle messaging from product behavior.
Product teams should care just as much. The same mechanism can push high-risk account flags into Slack, attach feature adoption signals to support cases, or update engineering workflows with customer impact context. When the warehouse can write back into operating systems, product strategy stops being separate from customer operations.
That's why the warehouse is often a goldmine you can't spend. It contains value, but value locked in analysis isn't the same as value realized in operations.
Reverse ETL is the spending mechanism. It turns a model from something you admire in a dashboard into something a team can act on before the moment passes.
Understanding Hightouch Reverse ETL and Data Activation
The cleanest way to understand hightouch reverse etl is to stop thinking about pipelines for a minute.
Think about your warehouse as a central kitchen. Raw ingredients arrive from product analytics, billing systems, support tools, and CRM data. Your data team cleans them, combines them, and turns them into something useful: churn scores, lead scores, product-qualified account lists, feature adoption models, LTV estimates, and usage summaries.
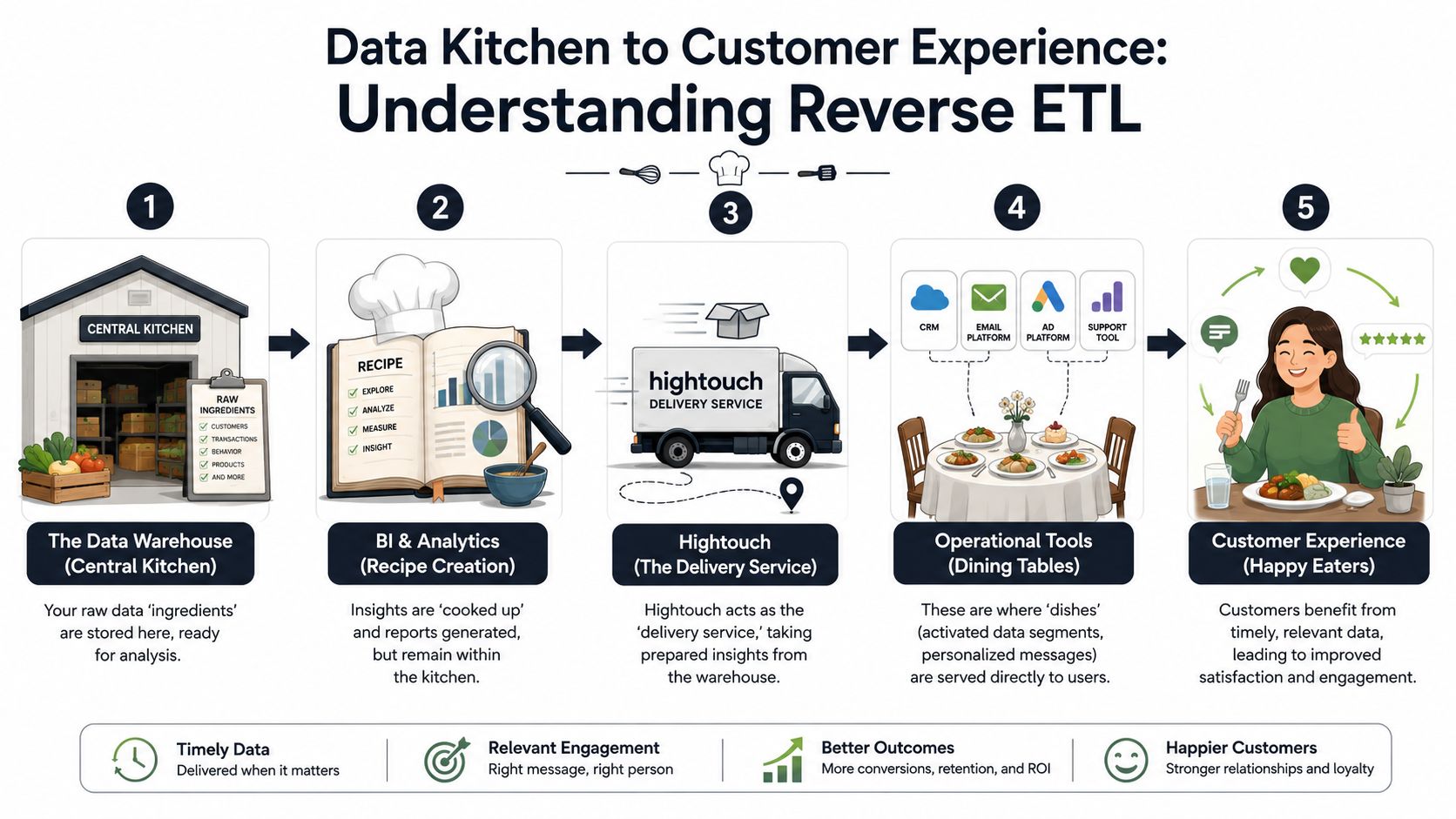
Traditional ETL loads the kitchen
Traditional ETL and ELT bring data into the warehouse. That's how the kitchen gets stocked.
Reverse ETL moves modeled data out of the warehouse and into business tools. That's the delivery layer. The destination might be Salesforce, Zendesk, an ad platform, a lifecycle tool, or an internal operational system.
Hightouch describes its platform as a modern reverse ETL product that connects cloud warehouses to tools used by sales, marketing, support, and operations teams. In its product documentation, Hightouch says it can sync data to 300+ destinations in real time or on a recurring schedule, and it supports warehouse-native workflows like selecting tables or writing SQL, mapping fields, and launching pipelines in minutes rather than weeks through its reverse ETL platform overview.
That matters because the model doesn't need to stay in analytics. It can drive action where the work happens.
Data activation is the operating idea
Data activation is the broader concept. It means taking trusted warehouse data and making it useful in downstream workflows.
A few examples make the distinction practical:
- A churn score in the warehouse is analysis.
- That churn score synced into Salesforce for the account owner is activation.
- That same score pushed into a support queue to prioritize outreach is activation.
- A feature adoption model sent to a campaign tool to trigger onboarding is activation.
Here's a simple way to evaluate readiness. If your warehouse models are still inconsistent or brittle, fix that first. A sync layer will amplify good data, but it also amplifies bad definitions. Teams dealing with inconsistent upstream records should address those data quality issues in operational workflows before they automate downstream actions.
A short demo helps make the concept more concrete:
Why Hightouch fits the modern stack
Hightouch's model is warehouse-native. That's the core appeal. The business logic stays close to the data team's source of truth instead of being rebuilt by hand in every downstream platform.
Good reverse ETL setups don't create a second analytics system inside your CRM or marketing tool. They deliver the warehouse result, not a parallel version of it.
For product and growth teams, that means less time arguing over definitions and more time acting on agreed signals. The warehouse remains the place where metrics are defined. Hightouch becomes the mechanism that distributes those metrics into live workflows.
How Hightouch Works Core Architecture and Features
The mechanics of hightouch reverse etl are straightforward once you break them into stages. The platform sits between your warehouse and the operational tools that need warehouse-derived data. The value comes from making that path reliable, repeatable, and manageable by more than one engineer.
Source, model, map, sync
Most deployments follow a four-part flow.
Source connection
Hightouch connects to the warehouse that already holds your modeled data. In practice, this only works well if your warehouse structure is understandable. If your team needs a cleaner way to document marts, ownership, and downstream dependencies before activation starts, a set of data architecture diagrams for modern teams usually pays off quickly.
The reverse ETL layer shouldn't be your first attempt to discover where customer truth lives.
Model definition
Next, you define the data to send. At this stage, mature teams separate reusable business models from export-specific models.
For example, keep your durable product usage model in dbt or SQL. Then create a slimmer export model for a destination like Salesforce or Zendesk that handles destination-specific field names, formatting, and grain. That keeps operational syncing from polluting core analytics logic.
If your warehouse also includes semi-structured records from forms, intake documents, or uploaded files, this often becomes part of activation work. Teams handling that kind of upstream data may find a guide on Snowflake document ingestion useful because document extraction quality affects how usable those records are once they're modeled for downstream syncs.
Field mapping
After the model is defined, warehouse columns are mapped to fields in the destination system.
This is the step where projects either stay disciplined or become fragile. A clean mapping strategy answers a few questions early:
- Which key matches the destination record
- Which fields are source-of-truth fields versus convenience fields
- What happens when values are null
- Which updates should overwrite existing destination values
If you skip those questions, you get syncs that technically run but create confusion in the business tool.
Sync behavior
Last, you decide how and when data moves. Some use cases are fine on a scheduled cadence. Others need low latency.
Hightouch marked a major architectural shift with the launch of Streaming Reverse ETL in 2024, which the company described as “Reverse ETL 2.0.” Hightouch says the architecture is “always on,” streams new data continuously, and can deliver end-to-end latency on the order of seconds for simple real-time use cases in its Streaming Reverse ETL announcement.
What changed with streaming
Older reverse ETL patterns were mostly scheduled jobs. They ran at intervals, checked for changes, and pushed diffs. That works for many CRM enrichment use cases, but it's weak for product-led workflows where timing matters.
According to Hightouch, streaming use cases include abandoned-cart campaigns, conversion events, onboarding emails, lead routing, and operational alerts in the same announcement above. That shift matters because the practical boundary between analytics and operations gets much thinner when the sync is always on.
The decision isn't “real time or batch” as a matter of prestige. It's whether acting later changes the outcome.
Features that matter in practice
The most useful capabilities aren't just connector counts. They're the ones that keep operational data movement sane.
A strong setup usually depends on:
- Warehouse-native model control so analysts and analytics engineers can work in SQL or dbt.
- Clear field mapping so business systems receive data in the shape they expect.
- Scheduling and streaming options so each workflow gets the latency it requires.
- Monitoring and debugging so failed syncs are visible before users notice stale records.
- Audience or segment tooling so non-technical teams can operate within approved data structures without redefining core metrics.
Hightouch has also shown compatibility with major ecosystems beyond a single warehouse pattern. In a Databricks partnership post referenced by the company's streaming history, it was used to move analytics data into business platforms while reducing pipeline maintenance and supporting data models, product usage data, and event data. That's the kind of operational detail architects care about because it signals whether a tool can support more than lightweight marketing syncs.
Driving Business Impact with Hightouch Use Cases
The easiest way to misuse reverse ETL is to think of it as a connector project. It's not. It's an operating model for getting trusted warehouse logic into business systems where people can make faster decisions.
The better question is always: what action changes when this model becomes available in the destination tool?
Sales example with product-qualified signals
A sales team usually has CRM activity, account ownership, and pipeline stage. What it often lacks is live product context.
Suppose the warehouse model identifies accounts that hit a product usage threshold associated with expansion interest. That model becomes your product-qualified account signal. Hightouch syncs it into Salesforce so the account executive sees it on the account record, and a workflow can create a task for follow-up.
That changes sales behavior in a practical way. Reps no longer rely only on form fills or late-stage intent. They work from product evidence.
Marketing example with behavior-based audiences
Marketing teams often segment on demographics, lifecycle stage, or broad firmographic rules because those fields are easy to access. The warehouse usually knows more.
Say the model identifies users who adopted one feature but stalled before the next critical step. Hightouch can push that audience into an ad platform or lifecycle tool so marketing reaches people based on product behavior instead of static profile data. The message gets tighter because it reflects where the user is.
The win isn't “more campaigns.” It's fewer generic campaigns.
Reverse ETL works best when the warehouse model captures intent or risk that the destination system can't infer by itself.
Customer success example with health context
Customer success teams live in systems like Salesforce, Gainsight, Zendesk, or support consoles. They need context before the call starts, not after an analyst replies to a request.
A warehouse model might combine support volume, feature adoption, seat utilization, and recent usage changes into a health classification. Hightouch syncs that classification into the system the CSM already uses. The same account can then route into a renewal playbook, escalation queue, or save motion.
That's much more useful than a dashboard that says “account health is declining” with no operational follow-through.
Product and support example with issue prioritization
Product intelligence becomes more interesting than standard GTM activation.
A warehouse model can detect that customers who experience a specific failure pattern are more likely to open repeated support tickets, stop using a workflow, or delay expansion conversations. Hightouch can send that signal into support or engineering tools so the issue isn't just visible in analytics. It becomes an operational priority with customer context attached.
That creates a loop product teams usually struggle to build manually. Warehouse analysis informs day-to-day triage.
Hightouch Reverse ETL Use Cases by Department
| Team | Data Model (from Warehouse) | Destination Tool | Business Outcome |
|---|---|---|---|
| Sales | Product-qualified account score | Salesforce | Reps prioritize outreach based on product behavior |
| Marketing | Feature adoption audience | Ad platform or lifecycle tool | Campaigns target users with relevant in-product context |
| Customer Success | Customer health model | CRM or support platform | CSMs intervene earlier with better account visibility |
| Support | Escalation risk or issue severity model | Zendesk or Slack | Agents triage with richer customer and product context |
| Product | Feature friction or workflow failure model | Jira, Linear, or Slack | Teams prioritize roadmap and bug response using real usage evidence |
| Operations | Account status or lifecycle model | Internal ops system | Teams standardize follow-up and handoffs across functions |
What tends to work and what doesn't
Some use cases produce value fast. Others stall because the organization isn't ready.
Usually works well
- Single-entity syncs where the key is clear, such as account, user, or contact.
- High-signal models that affect a real workflow, not vanity enrichment.
- Destination-specific outputs aligned with what the receiving team can act on.
Usually struggles
- Overstuffed syncs that try to send every field “just in case.”
- Weakly defined metrics that are still debated internally.
- No owner on the business side after the sync is live.
A good reverse ETL program improves decisions because the right model lands in the right place. A bad one just creates more fields.
Implementing Hightouch A Stepwise Approach
Teams often treat reverse ETL rollout like a connector checklist. Connect warehouse. Pick destination. Map fields. Done. That approach creates activity, not adoption.
A useful implementation starts with one business motion that already has urgency and a clear owner. If there isn't a team waiting to act on the data, the sync will become background infrastructure no one values.
Start with a narrow win
The best first project is usually high-impact and low-complexity.
Good starting points include a churn-risk flag for account management, a product-qualified signal for sales, or a support-priority field based on known product behavior. These are easy to explain, easy to validate, and tied to workflows that already exist.
Avoid starting with a giant customer 360 sync. It sounds strategic, but it often hides unresolved issues in identity, grain, governance, and ownership.
Pick a use case where someone will notice within a week if the sync stops working.
Model first, then activate
If the source model is unstable, the reverse ETL layer will surface that instability everywhere.
That's why I push teams to separate three things:
- Core business logic in dbt or warehouse SQL
- Export logic that reshapes the model for a destination
- Operational rules for when and how the sync should run
That separation makes debugging much easier. When a Salesforce field looks wrong, you can tell whether the issue came from the business definition, the export transformation, or the sync itself.
Build governance early
Hightouch has expanded beyond pure reverse ETL into a broader activation stack, including composable CDP, streaming reverse ETL, identity resolution, real-time personalization, and Match Booster. Its positioning also emphasizes syncing to 300+ destinations in real time or on a recurring schedule, as discussed in this Hightouch market review and decision analysis.
That expansion changes the governance conversation. You're not just managing sync jobs anymore. You're managing who can activate data, which layer owns segmentation logic, and whether your company wants activation, diagnosis, or prioritization to be the primary operational system.
A few governance rules help immediately:
- Define sync ownership by business process, not just by destination app.
- Use naming conventions that describe entity, purpose, and destination clearly.
- Document business purpose so every sync answers “why does this exist?”
- Set failure alerts for the people who depend on the output, not only the data team.
- Review field sprawl regularly so destinations don't become warehouses in disguise.
Decide where Hightouch should stop
This is the under-discussed implementation question.
Hightouch is strong when the job is to operationalize trusted warehouse outputs into downstream tools. It's less compelling as a place to resolve every problem in data engagement strategy. If your real need is event diagnosis, prioritization of feedback, or workflow orchestration driven by emergent product signals, another layer may need to sit alongside it.
That's not a weakness. It's architectural clarity.
Use Hightouch when the warehouse already knows something important and another system needs that answer now. Don't force it to become the only intelligence layer in the stack.
Supercharging SigOS with Hightouch Reverse ETL
Data teams frequently use reverse ETL to enrich GTM systems. A more compelling approach is leveraging it to create a closed loop between customer behavior, customer feedback, and product action.
That's where hightouch reverse etl becomes part of product intelligence instead of just revenue operations plumbing.

The closed loop product teams actually need
In many organizations, product insight is fragmented.
Support tools hold ticket language. Sales recordings hold objection patterns. Product analytics shows feature usage. CRM records show account tier and renewal context. Product managers pull these threads together manually, often too late to shape intervention.
A product intelligence layer changes that by analyzing qualitative and behavioral signals together, then writing the resulting signals into the warehouse. From there, Hightouch can distribute those signals into operating systems.
The pattern looks like this:
- Feedback and behavior are analyzed together
- High-signal outputs are written to the warehouse
- Hightouch syncs those outputs into the tools where teams take action
- Teams respond in product, support, sales, and engineering workflows
- New outcomes feed back into the warehouse
This is what turns reverse ETL into a strategic product lever.
Where the pairing becomes useful
The combination is strongest when the signal is too important to leave in a dashboard.
Examples of useful outputs include:
- Churn risk indicators based on support language and declining usage
- Feature request priority signals tied to account value or expansion context
- Bug severity signals informed by recurring customer friction
- Adoption blockers detected from behavior patterns and customer conversations
A product intelligence platform can surface those as structured warehouse outputs. Hightouch then carries them into the right destination.
For teams evaluating this type of workflow, it helps to understand the shape of a dedicated product intelligence layer and its integrations through the SigOS platform capabilities overview.
Concrete workflows that create urgency
Here's where this gets practical.
A high-value account starts showing behavior associated with churn. Support interactions also shift in tone, and product usage drops around a specific workflow. The resulting warehouse signal marks the account for immediate review. Hightouch pushes that status into Salesforce for the account owner and into Slack for a shared escalation channel. Customer success and product can now respond using the same signal.
Or consider a recurring product defect. Support tickets, call transcripts, and usage disruption point to the same issue. The warehouse receives a structured priority output. Hightouch syncs that context into Jira or Linear so the engineering team sees not just that a bug exists, but why it matters to customers and revenue conversations.
The strongest reverse ETL use cases don't just move fields. They move organizational attention.
Why this matters for roadmap quality
Product teams often say they want to be data-driven. In practice, they're usually dashboard-informed and meeting-driven.
A tighter loop changes that. Warehouse models no longer sit passively until a monthly review. High-signal product intelligence can enter the same systems where support triages, sales renews, and engineering prioritizes. That makes strategy less abstract.
The result isn't just faster action. It's better prioritization because the signal reaches the function that can respond while the evidence is still fresh.
The Future of Actionable Data
The modern warehouse can't just be a reporting system anymore. It has to serve as an operational hub for decisions that need to happen inside business tools, product workflows, and customer-facing systems.
That's why hightouch reverse etl matters. It closes the distance between modeled insight and operational action. Instead of asking teams to visit analytics, it delivers analytics into the tools where they already make decisions.
What changes next
The category is also getting broader.
Reverse ETL used to be discussed mainly as the last mile for sales and marketing syncs. That's still important, but the more meaningful shift is how activation starts to overlap with product intelligence, orchestration, and prioritization. The hard question isn't whether you can move warehouse data downstream. It's whether you're moving the right signals into the right workflows with enough context to change outcomes.
That's where mature teams will separate themselves.
The practical takeaway
Use reverse ETL when you already trust the warehouse model and need another system to act on it. Keep business logic clean, keep governance tight, and tie every sync to a specific operational decision.
When you do that well, the warehouse stops being a place where insight goes to wait. It becomes the system that informs the next email, the next support response, the next sales call, and the next product priority.
That's the true promise of data activation. Not more pipelines. Better decisions, made closer to the moment when they still matter.
If your team wants to connect customer feedback, product usage, and revenue signals into a clearer product prioritization loop, take a look at SigOS. It's built for teams that need to identify high-signal patterns across support, sales, and behavior data, then turn those signals into actions product and growth teams can use.
Keep Reading
More insights from our blog



Ready to find your hidden revenue leaks?
Start analyzing your customer feedback and discover insights that drive revenue.
Start Free Trial →