AI Product Requirements Document: A Practical B2B Guide
Build a better AI Product Requirements Document. This practical guide for B2B SaaS shows you the key sections, metrics, and examples you need.

The most popular advice on an AI product requirements document is also the least useful: take your normal PRD template, add a few lines about the model, and let a drafting tool fill in the rest.
That approach breaks the moment the feature stops behaving like regular software.
A settings page is deterministic. You define fields, validations, and system responses. A churn predictor or feature analysis engine is probabilistic. It produces scores, rankings, summaries, and recommendations with uncertainty baked in. If your PRD treats both the same way, the team ends up arguing about the wrong things. Engineering asks what to build, data science asks what “good” means, and support asks what happens when the model is wrong.
A strong AI product requirements document doesn't just describe functionality. It captures where AI is appropriate, how the system should behave under uncertainty, which outputs are acceptable, and how the team will monitor drift after launch. If you're still writing AI requirements as if you're specifying buttons and API fields, you're documenting the interface while ignoring the actual product risk.
Why Your Standard PRD Fails for AI Products
Most PRD templates assume the system will do exactly what you specify. That's fine for an export button. Click it, generate a file, show a success state, handle an error if the request fails.
AI products don't work like that.
A churn prediction feature might rank accounts by risk, but it won't be perfectly certain. A feature analysis workflow might cluster support tickets into themes, but some tickets will be ambiguous, mixed, or noisy. The hard product work isn't only defining the user flow. It's deciding when AI should make a judgment, when deterministic logic should take over, and how the product should behave when confidence is weak.
The problem with most advice on an AI product requirements document is that it stays tool-centric. It tells you how to generate a nicely formatted doc, but not how to make the core AI product decisions teams struggle with. As Beam notes in its review of AI PRD guidance, many teams still need help deciding when to use AI versus deterministic logic, how to specify behavior under uncertainty, and what failure modes to document.
Standard PRDs assume certainty. AI PRDs have to manage uncertainty on purpose.
That's why a generic template copied from a normal SaaS feature usually produces vague requirements like “surface churn risks” or “summarize customer feedback.” Those aren't requirements. They're aspirations.
If your team needs a baseline structure for a traditional product document first, use a practical reference like this guide on how to write a PRD. Then rebuild it for AI. Don't just relabel old sections and hope the model work will sort itself out later.
The New Foundation From Problem Statement to AI Hypothesis
A standard problem statement usually says what user pain exists and what feature should address it. For AI, that's not enough. You also need to explain why AI is the right mechanism for solving that problem.

Start with the job that rules can't handle well
In B2B SaaS, teams often reach for AI too early. They see lots of unstructured data, then assume a model must be involved. Sometimes a rule engine, thresholds, or a better workflow solves the problem with less risk.
A better opening section asks three questions:
- **What decision is the user trying to make?**For churn prediction, that might be “Which accounts need proactive outreach this week?”
- **Why does current software fail?**Maybe health scores depend on rigid rules and miss signals hidden in ticket tone, usage drops, or renewal conversations.
- **Why is AI a fit here?**Because the inputs are messy, patterns shift, and the product needs probabilistic ranking rather than binary logic.
If you can't answer the second and third questions clearly, you probably don't need AI yet.
Rewrite the problem statement as an AI hypothesis
This is the shift that changes the rest of the document. Instead of saying “build churn prediction,” write a testable hypothesis about user value and model behavior.
For example:
AI hypothesis: If the product can analyze account usage, support interactions, and customer sentiment together, customer success managers can identify at-risk accounts earlier than they can with static health rules alone.
That framing forces better product conversations. It pushes the team to define what “earlier” means in workflow terms, what inputs matter, and what action the user should take once the system produces a risk signal.
This mindset lines up with broader modern product strategy work. A practical reference is the ThirstySprout product development playbook, especially if you need a sharper link between user problems, prioritization, and delivery discipline.
Define users by error tolerance, not just persona
Traditional persona sections describe role, goals, and pain points. For AI features, add error tolerance.
A VP of Customer Success reviewing a churn-risk dashboard might tolerate some false positives if the output is a prioritization aid. The same person won't tolerate opaque account downgrades that trigger automation without review. A support leader using feature analysis may accept imperfect theme clustering, but not category labels that hide urgent defects.
That means your PRD should include questions like:
- What kind of mistakes are acceptable? Low-risk over-flagging may be fine. Silent misses may not.
- How visible is the AI output? Internal recommendations have different standards than customer-facing decisions.
- Who can override the system? If the answer is “nobody,” the bar should be much higher.
For teams exploring broader workflow changes, this article on AI for product development is useful because it frames AI as part of decision-making, not just document generation.
Success starts as workflow change
Don't define success only as “model accuracy.” Start with user behavior.
For a churn use case, success might mean the CSM can review a ranked list, understand the reason codes, and take action without opening five different tools. For feature analysis, success might mean the PM can distinguish a noisy request from a revenue-linked pattern without reading every ticket manually.
Then, and only then, connect that workflow improvement to model evaluation later in the PRD.
Specifying the Brain Model Behavior Data and Guardrails
Once the AI hypothesis is clear, the PRD needs a section that describes the system's brain. Here, many otherwise solid product docs fall apart. They describe UI states in detail, then reduce the model to a sentence like “use AI to classify churn risk.”
That isn't enough to guide engineering, data science, design, legal, or support.
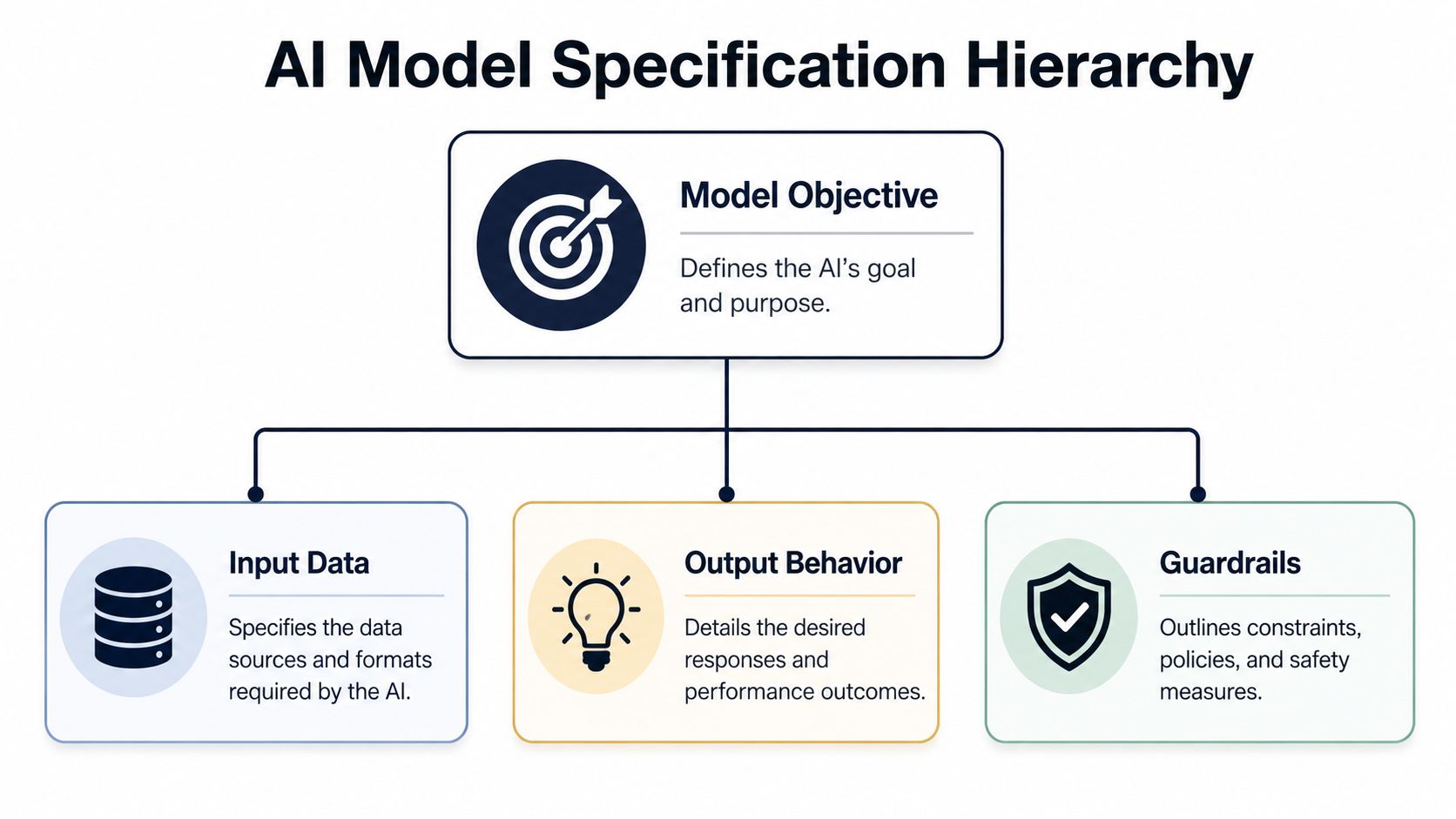
Published guidance on modern AI PRDs explicitly calls for AI-specific sections beyond standard product documentation, including an eval framework, guardrails, model strategy, data requirements, responsible AI considerations, and a monitoring or adaptation plan. One framework recommends at least six additional sections beyond the usual core PRD structure, which reflects the shift from a static feature spec to a living operational spec in production in this AI PRD guide.
The model spec is a product spec
Treat the model like a first-class product component. That means documenting four things in plain language.
InputsState exactly what the model sees. For churn prediction, that might include CRM fields, support ticket text, usage logs, renewal metadata, and product event trends. Don't stop at naming sources. Specify freshness, format, ownership, and gaps you already know about.
Output behaviorDescribe what the system should return and how it should be consumed. Is the output a risk score, a ranked list, a category label, a summary, or a recommendation? Does it need explanation text? Can users see confidence or only a final decision?
ConstraintsDocument latency expectations, transparency requirements, review workflows, and any reasons a simpler rules-based system must remain in the loop. In feature analysis, for example, you may want AI to cluster themes but leave final prioritization to product managers.
GuardrailsList what the system must not do. This is the most neglected part.
A practical example helps. If you're working on sentiment or theme extraction from customer conversations, a piece like using AI to decode emotional feedback is useful because it shows how easily tone analysis can drift into overconfident interpretation without clear boundaries.
Put the key differences in one place
| Component | Traditional PRD (e.g., Export Button) | AI PRD (e.g., Churn Predictor) |
|---|---|---|
| Primary requirement | Generate a CSV when user clicks Export | Rank accounts by predicted churn risk using approved inputs |
| Inputs | User click, selected filters | Usage logs, CRM records, support interactions, account metadata |
| Expected behavior | Deterministic and fixed | Probabilistic, thresholded, may vary by input quality |
| Edge cases | Empty export, timeout, permissions | Missing data, conflicting signals, low confidence, stale records |
| Acceptance logic | Feature works or fails | Quality thresholds, review path, fallback handling |
| Failure mode | Export fails visibly | Model may be wrong while still producing plausible output |
| Fallback | Retry or error message | Route to manual review, rules-based backup, suppress output |
| Post-launch needs | Bug tracking | Monitoring, recalibration, rollback criteria |
Data quality belongs in the PRD
The model's output quality depends heavily on what goes in. That's obvious, but teams still bury data assumptions in technical docs after the PRD is approved.
For a feature analysis product, specify questions like:
- Which sources are authoritative? Zendesk might reflect pain frequency, but sales call notes might better indicate revenue impact.
- How noisy is the text? Ticket tags, internal notes, and copied boilerplate can distort patterns.
- What labeling strategy will be used? Human review, historical outcomes, heuristic labels, or a mix.
- What data is excluded? If you won't use certain customer fields, say so.
A PRD that doesn't define data boundaries creates false alignment. Product thinks the model will infer rich patterns. The ML team later discovers the source data is inconsistent, duplicated, or too sparse for the intended behavior.
Practical rule: If a model's output would change materially when one input source disappears, that dependency belongs in the PRD.
Guardrails are where product judgment shows up
Guardrails aren't just compliance text. They're product decisions about trust.
For churn prediction, useful guardrails may include:
- No autonomous account escalation: The system can recommend intervention, but it can't trigger customer communication without human review.
- No unsupported explanation: If the model can't justify a risk flag with observable evidence, suppress the explanation rather than inventing one.
- No score display on weak input: If critical account data is missing, show “insufficient signal” instead of a misleading low-confidence rank.
For feature analysis, your guardrails might look different:
- Don't merge opposite intents: Requests to “make reporting simpler” and “add advanced reporting controls” may mention the same feature area but reflect different product needs.
- Separate bugs from requests: Don't let thematic clustering bury urgent defects inside broad feedback groups.
- Preserve traceability: Every synthesized theme should link back to source evidence the PM can inspect.
A short walkthrough helps anchor this thinking:
Defining Good Evaluation Metrics and Acceptance Criteria
The hardest sentence in an AI PRD is often “this feature is done.”
That sentence is hard because model quality and product value aren't the same thing. A team can improve a classifier offline and still ship a feature users don't trust. It can also launch a useful workflow with an imperfect model if the review path and UX are designed well.
Separate model signals from business outcomes
Your PRD needs both.
Model signals tell you whether the AI is behaving acceptably on the task. For churn prediction, that could include precision, recall, calibration, explanation quality, or confidence reliability. For feature analysis, it could include clustering coherence, label quality, duplicate detection quality, or source attribution quality.
Business outcomes tell you whether the product change mattered. Did customer success teams act faster? Did PMs identify high-signal requests earlier? Did support and product align on the same priorities more consistently?
Don't collapse these into one metric. If you do, the team either over-optimizes for data science benchmarks or hand-waves model quality because business value sounds promising.
Require measurable quality signals per feature
Published guidance for AI products recommends that the PRD define three to five measurable quality signals per feature, along with explicit measurement methods such as algorithmic checks, AI-as-judge, or human review, plus pass thresholds for each signal in this AI PRD framework.
That's a strong operating rule because it forces specificity.
For a churn predictor, those quality signals might include:
- Ranking usefulness: Human review checks whether the top-risk accounts look intervention-worthy.
- Explanation usefulness: Reviewers judge whether the stated drivers are understandable and grounded in real account signals.
- Low-confidence handling: Algorithmic checks verify that weak-input accounts are routed to fallback states instead of being scored normally.
- Freshness of predictions: System checks confirm scores are updated on the intended cadence.
For a feature analysis engine, the signals could differ:
- Theme consistency: Human reviewers compare whether similar tickets land in the same cluster.
- Evidence traceability: Algorithmic checks confirm each theme links to underlying source items.
- Separation quality: Reviewers test whether bugs, requests, and praise remain distinct enough for action.
- Priority usefulness: PMs judge whether the ranked output supports roadmap decisions better than raw queues.
Good acceptance criteria describe how you'll inspect quality, not just what you hope the model will do.
Write acceptance criteria like an operating agreement
Avoid vague language like “results should be accurate” or “summaries should be useful.” Those statements create arguments later because every stakeholder interprets them differently.
A better pattern is:
| Area | Acceptance criterion example |
|---|---|
| Prediction output | System returns ranked risk output only for accounts with required input coverage |
| Confidence handling | Low-signal accounts are suppressed or clearly marked for manual review |
| Explanation | Each surfaced risk includes concise, reviewable rationale tied to observable data |
| Review workflow | Customer success users can inspect and override recommendations |
| Logging | Product and engineering can audit why a result was shown |
If your team struggles to connect feature quality to broader product reporting, it helps to align these requirements with a KPI discipline such as this guide to a key performance indicator report template.
Review on a cadence that matches volatility
AI requirements age faster than normal feature requirements. A sensible pattern is to review strategic elements quarterly, tactical thresholds monthly, and technical details when major model changes occur. That layered cadence is recommended in published AI PRD guidance because it keeps the document aligned with moving model behavior without rewriting the whole spec every sprint.
Real-World Examples AI PRD Snippets for B2B SaaS
Templates are easy to copy and hard to use. Snippets are better because they show the level of precision the team needs.
The examples below are intentionally short. In practice, teams often use AI to draft first-pass sections, user stories, and acceptance criteria, but the PM still has to review, edit, and own the final document with company-specific context, technical constraints, and risk checks. That's consistent with published guidance on using generative AI for PRD work, including the recommendation to provide clear context such as target user, problem, key features, and success metrics when creating a draft in this product leadership guide.
Snippet one for churn prediction
Product problemCustomer success managers rely on static health scores that miss signals spread across product usage, ticket history, and renewal context. As a result, teams react late and spend time reviewing healthy accounts while true risks are buried.
Why AI is appropriateRisk signals are distributed across structured and unstructured inputs. Rule-based scoring can capture some known patterns, but it doesn't adapt well to mixed signals or shifting account behavior.
AI hypothesisIf the system combines behavioral and support signals into an account-level risk ranking, CSMs can focus review time on the accounts most likely to need intervention.
Example requirement block
- Primary user: CSM managing a named book of business.
- Decision supported: Which accounts need manual review this week.
- Required inputs: Product usage events, CRM account status, support ticket history, renewal date context.
- Output: Ranked list of accounts with risk category and plain-language drivers.
- Fallback behavior: If required inputs are missing or stale, do not rank the account normally. Mark it for manual inspection.
- Out of scope: Automated outreach, contract change recommendations, or customer-facing score exposure.
Example guardrails
- The system can't trigger direct customer communication.
- The system can't generate explanation text that isn't grounded in observed account data.
- The UI must let the CSM dismiss or override a flag.
Snippet two for feature analysis
This use case is common in B2B SaaS because product teams sit on a pile of tickets, chat logs, call notes, and win-loss feedback, but struggle to turn that into roadmap signal.
Product problemProduct managers and support leads see the same feedback in different tools and with different urgency. High-volume complaints, strategic requests, and defect reports get mixed together, which slows prioritization.
Why AI is appropriateThe main challenge isn't storage. It's interpretation across large volumes of noisy text with overlapping themes, inconsistent language, and uneven business context.
AI hypothesisIf the system groups feedback into evidence-backed themes and separates bugs, requests, and sentiment, PMs can prioritize with less manual triage and better stakeholder alignment.
Example requirement block
| Field | PRD snippet |
|---|---|
| Primary user | Product manager responsible for discovery and roadmap intake |
| Inputs | Support tickets, chat transcripts, sales call notes, customer interview notes |
| Output | Clustered themes with linked source evidence, trend labels, and suggested priority bands |
| Review path | PM validates top themes before they appear in team planning workflows |
| Failure mode to prevent | Distinct requests merged into one vague cluster |
| UX requirement | User can open any theme and inspect source artifacts behind it |
The most useful AI PRDs don't pretend the model is the product. They specify how the model supports a user decision.
What works and what doesn't
What works
- Narrow decision framing: “Help PMs review the top recurring onboarding complaints” is better than “analyze all feedback.”
- Visible evidence links: Users trust synthesis more when they can inspect source artifacts.
- Manual review for high-impact outputs: Especially when results affect roadmap prioritization or account treatment.
What doesn't
- Single giant requirement: “Use AI to prioritize customer feedback” hides too many product decisions.
- No fallback behavior: The model will eventually see sparse, contradictory, or low-quality inputs.
- Pretend confidence: Users abandon AI features that sound certain when they should sound cautious.
Beyond the Launch The Living PRD for Monitoring and Rollbacks
An AI product requirements document shouldn't expire at launch. It should keep governing the product when the model starts seeing real production data, edge cases, and behavior shifts.
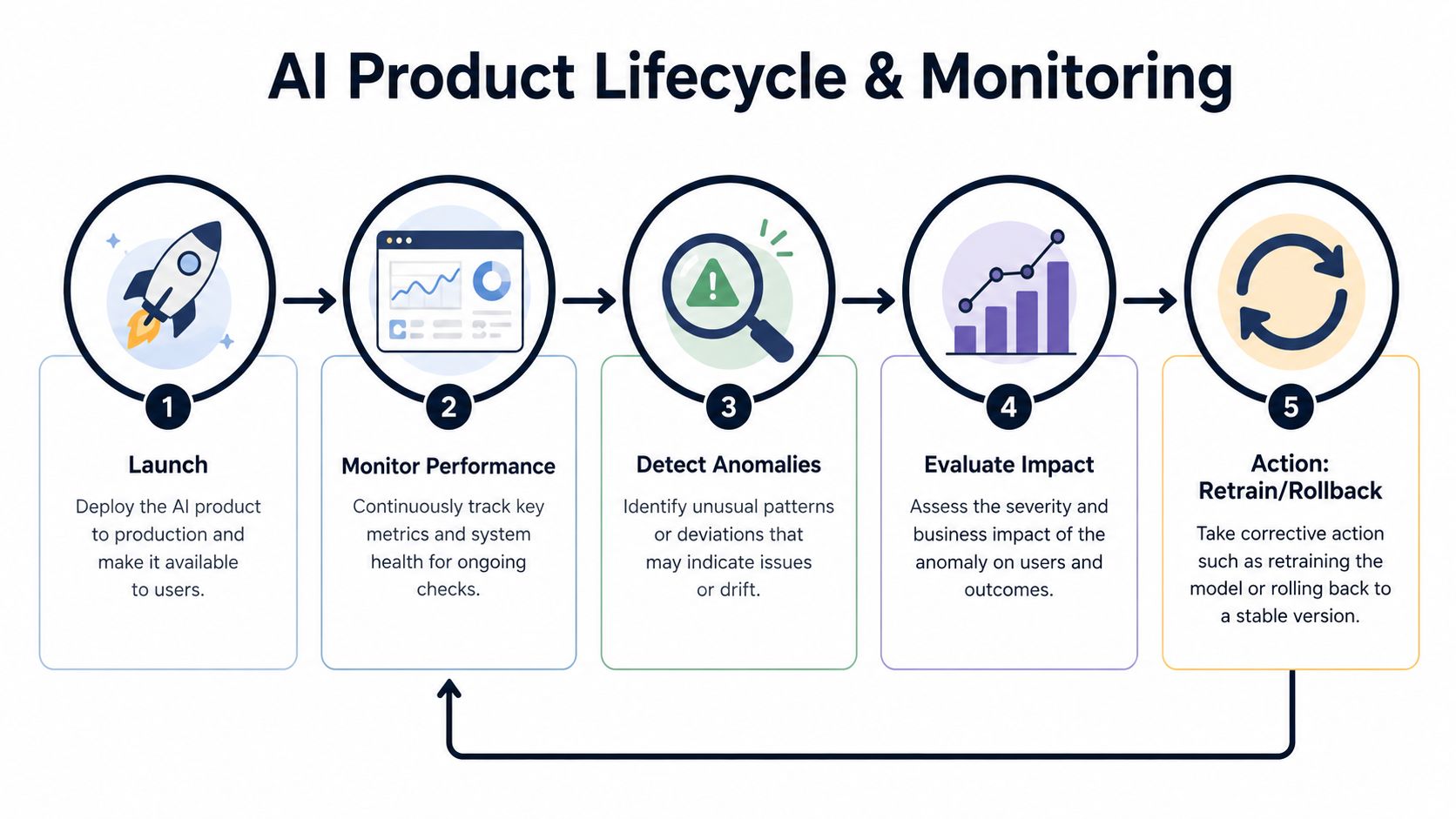
The teams that struggle after launch usually made the same mistake earlier. They wrote the PRD as a delivery artifact, not an operating tool. For AI, that means they forgot to define who watches quality, what signals indicate drift, when fallback modes activate, and who can approve rollback.
A living PRD should answer practical questions:
- What gets monitored in production? Prediction quality, input quality, user overrides, complaint patterns.
- What triggers action? A rise in suspicious outputs, evidence of stale inputs, or repeated operator distrust.
- What are the safe states? Manual review only, deterministic backup logic, or temporary feature suppression.
- Who owns updates? Product, engineering, data science, and operations each need named responsibilities.
If the PRD doesn't tell the team how to respond when the model behaves badly, it isn't finished.
The best AI products don't just launch. They adapt, degrade gracefully, and recover quickly.
If your team is drowning in tickets, call notes, and conflicting feature requests, SigOS helps turn that noise into actionable product intelligence. It connects feedback and behavioral signals so product, support, and growth teams can spot churn risks, revenue-linked issues, and roadmap priorities faster, without relying on gut feel alone.
Keep Reading
More insights from our blog



Ready to find your hidden revenue leaks?
Start analyzing your customer feedback and discover insights that drive revenue.
Start Free Trial →