SaaS Process of Operations: Define & Optimize for 2026
Define and optimize your process of operations in SaaS. Learn core components, key metrics, and how to convert customer feedback into revenue for 2026.

Your team probably has the same symptom most SaaS teams have when operations are loose. Sales forwards “must-have” feature requests in Slack. Support logs bugs in Zendesk. Success managers keep renewal risk notes in spreadsheets. Product managers try to piece it together in Jira, then leadership asks why roadmap decisions still feel subjective.
That isn't a prioritization problem first. It's a process of operations problem.
In SaaS, the raw material isn't steel or inventory. It's customer signals, behavioral data, incident data, delivery capacity, and all the messy context around why users stay, expand, or leave. If those inputs arrive in different systems with no consistent operating path, the team ships reactively. Work gets done, but the system doesn't learn.
Strong operators treat this as a design challenge. They build a process that takes noisy inputs, turns them into structured decisions, and ties those decisions to outcomes the business cares about, including retention, expansion, and revenue quality. That's the difference between a fast-moving company and a company that's merely busy.
Beyond the Factory Floor What Is a Process of Operations
When “process of operations” is mentioned, manufacturing often comes to mind. That framing is too narrow for a modern SaaS company.
The better definition is simpler. A process of operations is the repeatable system your company uses to turn inputs into outputs while keeping quality, speed, and learning under control. In a software business, those inputs include feedback, incidents, product usage, technical constraints, and strategic goals. The outputs are releases, fixes, decisions, customer communication, and measurable business impact.
That's why product operations and IT operations end up closer than many teams expect. In IT operations, the operating process commonly spans configuration, deployment, monitoring, remediation, and change management across infrastructure and applications, with automation used to reduce human error and help teams catch issues before they become larger incidents, as outlined in this overview of IT operations. The same operating logic applies to the product side. You need a path from signal to action, then from action to monitoring.
What it looks like when the process is missing
A weak operating process usually looks normal from the inside because everyone is working hard.
You'll see things like:
- Feedback without structure. Tickets, calls, NPS comments, and churn notes all exist, but nobody can compare them cleanly.
- Roadmap by anecdote. The loudest customer or largest internal stakeholder gets attention first.
- Slow recovery loops. Teams discover issues late because monitoring and remediation live far away from product decisions.
- No strategic traceability. Leadership can't answer which work reduced churn risk or generated revenue.
Practical rule: If your team can't explain how a support trend becomes a product decision, your process of operations is still informal.
Why SaaS teams should care
In software, scale punishes ambiguity. A messy process might survive when the product is small and the customer base is forgiving. It breaks once feedback volume rises, release complexity increases, and revenue teams start depending on product decisions to close deals and protect renewals.
A mature process of operations isn't bureaucracy. It's the operating layer that makes growth survivable.
The Core Components of a SaaS Operations Engine
The easiest way to improve operations is to stop thinking in isolated workflows. Think in systems.
A useful mental model comes from the Generic Statistical Business Process Model, which structures production into 8 phases and 44 sub-processes and treats quality control as part of the operating cycle from user needs through evaluation, as described in the GSBPM reference framework. SaaS teams don't need to copy that model exactly, but they should copy the discipline behind it. Inputs should be defined. Outputs should be reviewable. Evaluation should be built in, not bolted on later.
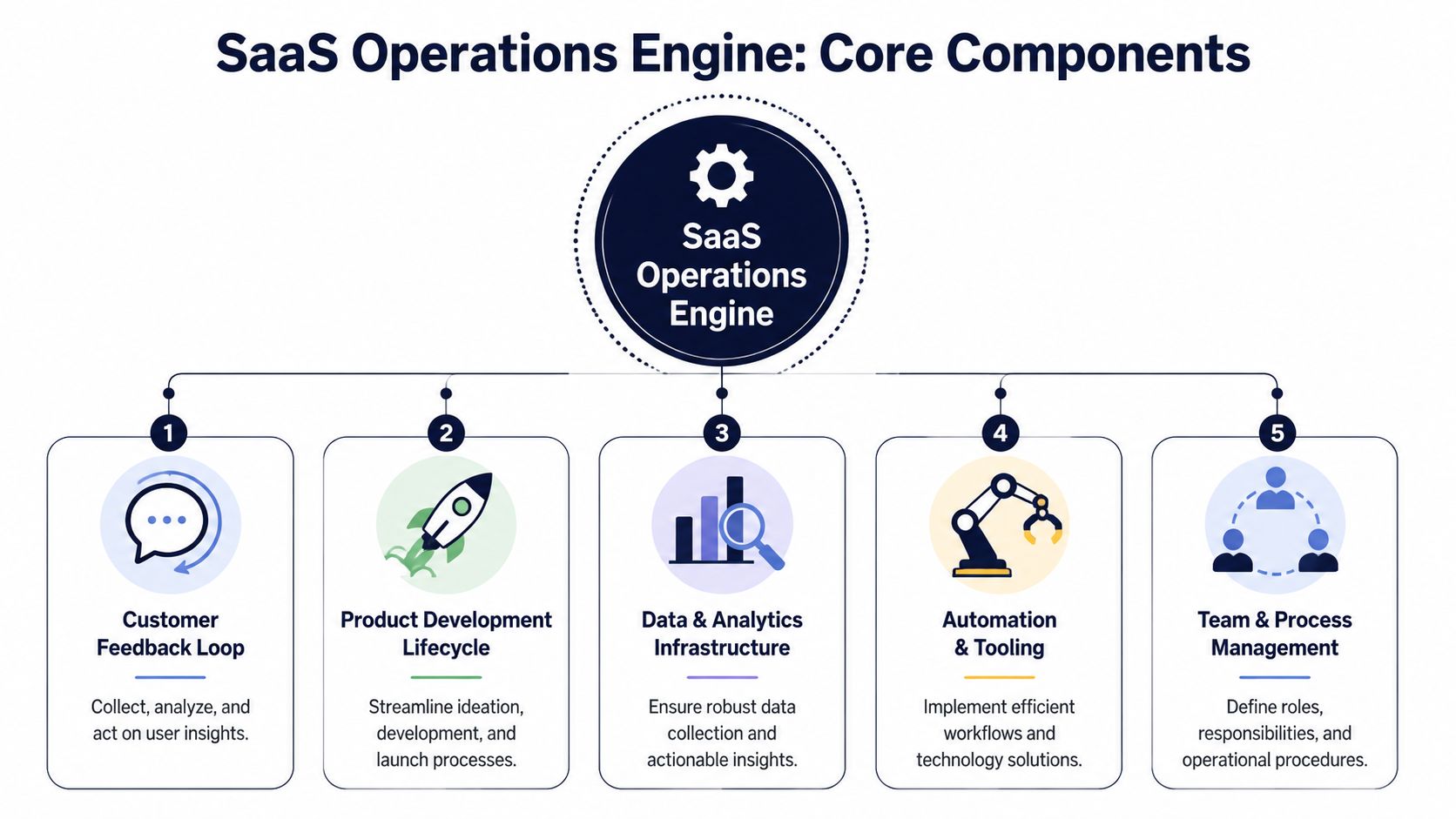
Input management
Most SaaS operating problems begin before prioritization. They begin at intake.
Product teams often have plenty of feedback and not enough usable signal. Zendesk may hold support pain points. Gong or call notes may hold sales objections. Success has onboarding friction. Analytics shows drop-off, but not always intent. If these streams never get normalized, the roadmap becomes an argument about whose evidence counts.
The fix is not “collect more.” The fix is to define what enters the system, in what format, with what metadata, and who owns triage.
A simple intake model should answer:
| Input type | Typical source | What to capture |
|---|---|---|
| Bug signal | Support ticket, chat, call | Account context, severity, affected workflow |
| Feature request | Sales, success, user interview | Desired outcome, impacted segment, urgency |
| Behavioral friction | Product analytics | Step where users stall or abandon |
| Reliability issue | Monitoring, incident review | Trigger, blast radius, remediation notes |
Process design
Once inputs are clear, the next job is deciding how work moves.
Many teams often overcomplicate things. They build approval chains instead of decision paths. Good process design defines handoffs, sequencing, and escalation rules. It also makes role clarity visible. Product owns prioritization logic. Engineering owns technical feasibility. Support owns signal quality at capture. RevOps or finance may help quantify commercial impact.
Good operations design reduces the number of decisions people have to improvise under pressure.
System build
Tools matter, but only after the workflow is explicit.
A typical SaaS stack might include Jira or Linear for delivery, Zendesk or Intercom for support, Slack for alerts, a warehouse or BI layer for analysis, and CRM data for account context. The mistake is assuming integration alone creates process maturity. It doesn't. Connected tools without a defined operating model just move confusion faster.
What works is building around a source-of-truth workflow. Every tool should answer one question: does it improve intake quality, routing, decision-making, or closed-loop communication?
Execution and delivery
Execution is where process gets exposed.
A healthy engine doesn't dump all validated work into the same queue. It separates categories. Bugs, reliability issues, strategic features, and customer-specific asks need different treatment paths. If they all flow through one generic backlog, urgent work crowds out valuable work and valuable work gets delayed because nobody wants to jump the line.
Use explicit lanes, clear service levels internally, and documented decision criteria. That creates predictability without slowing the team down.
Analysis and iteration
The operating system isn't done when code ships.
You need to evaluate whether the work changed customer behavior, reduced repeat complaints, improved reliability, or helped revenue teams move deals forward. Teams that skip this step usually drift back into opinion-led planning because they never prove what worked.
Review the process itself too. If triage is still manual, if issue definitions are inconsistent, or if high-value signals arrive too late, the process needs redesign, not more meetings.
Key Metrics and Signals That Signal Process Health
A process of operations should be judged by stability and decision quality, not by how full the sprint board looks.
The trap is counting outputs that are easy to report. Tickets closed. Story points burned. Releases shipped. Those metrics can describe activity while hiding broken prioritization. In SaaS, process health shows up in how predictably the team moves from issue detection to resolution, and whether that motion improves customer and commercial outcomes.
A useful principle from statistical process control is DPMO, or defects per million opportunities, calculated as (Total Defects / (Units × Opportunities per Unit)) × 1,000,000, with control charts and process capability analysis used to evaluate variation, stability, and whether a process can consistently meet specification limits, as explained in this Six Sigma statistics reference. Most product teams won't apply DPMO directly. They should use its mindset: don't judge the process by volume alone. Judge it by defects, consistency, and durability.
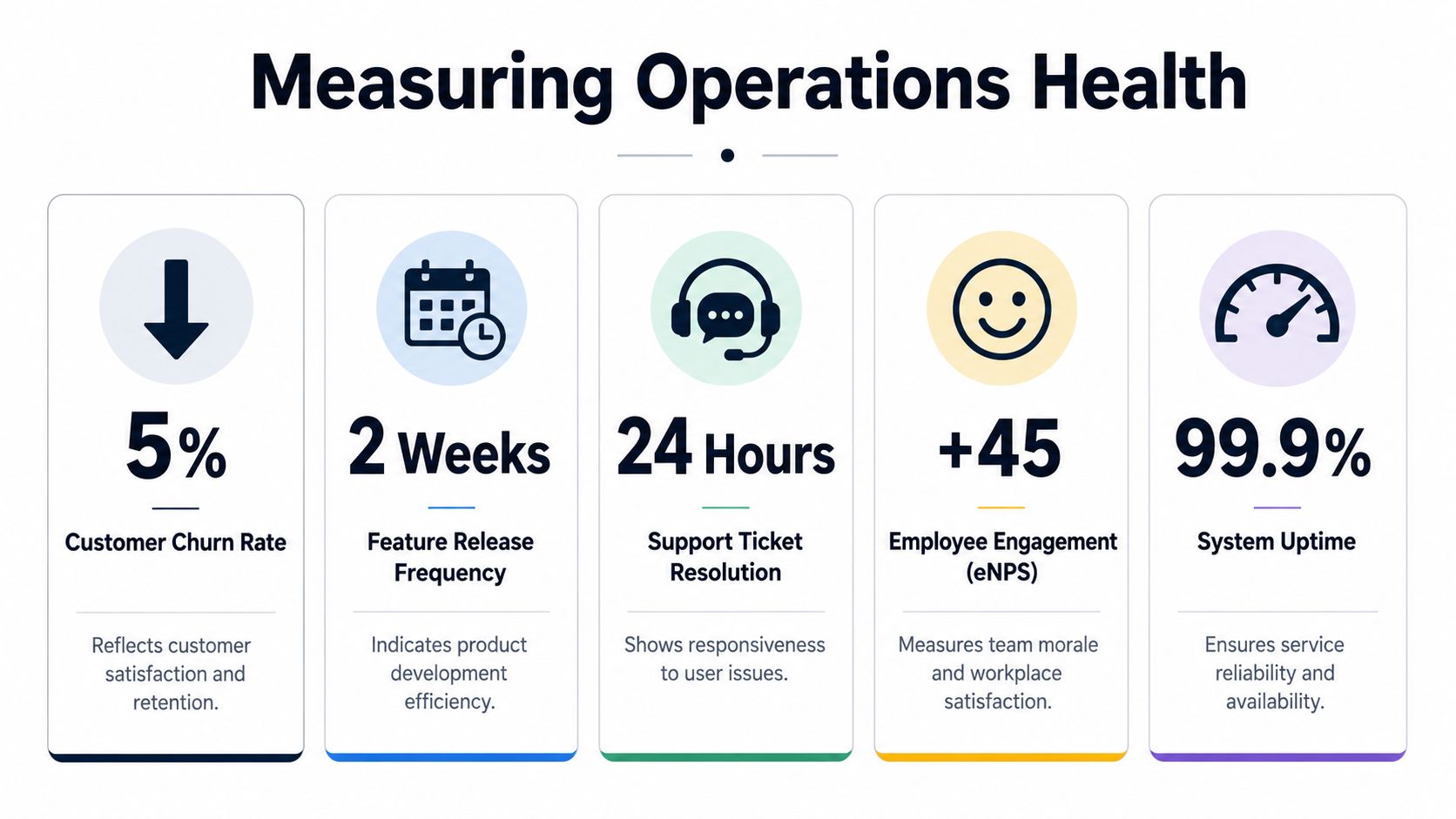
The metrics that actually matter
A strong operating dashboard usually combines delivery, quality, and business signals.
Focus on measures such as:
- Lead time for product decisions. How long does it take to move from validated signal to approved work?
- Cycle time for bug fixes. How quickly does the team resolve issues once they're accepted into delivery?
- Change failure patterns. Which releases create avoidable rework, support load, or rollback pain?
- Feedback recurrence. Are the same complaints returning after the team claims to have solved them?
- Commercial linkage. Which issues are tied to renewal risk, expansion blockers, or delayed deal movement?
The important shift is this: stop asking only “how much did we ship?” Start asking “what operational friction did we remove, and what did that change for the business?”
How to use control thinking in SaaS
Control charts sound industrial, but the idea translates well to software operations.
If bug resolution time swings wildly from week to week, your process isn't under control even if the average looks acceptable. If feature requests from enterprise accounts always leapfrog smaller but recurring pain points, your intake process is being distorted by escalation pressure. If support volume drops after a fix but churn conversations don't, you may have removed noise without removing business risk.
A practical review cadence can include:
| Signal | What to look for | What it often means |
|---|---|---|
| Stable cycle time | Predictable variation | Triage and delivery rules are working |
| Frequent spikes | Irregular delays | Hidden dependencies or poor intake quality |
| Repeat issue themes | Same complaint returns | Fixes are partial or root cause is misread |
| High output, weak adoption | Features ship, usage lags | Prioritization is disconnected from customer need |
Tie operations to revenue, not just effort
At this stage, mature product operations starts sounding different in executive reviews.
You don't need to present a pile of activity metrics. You need to show how operational work protects existing revenue and creates room for expansion. That may mean showing which bugs are concentrated among high-value accounts, which missing capabilities are stalling procurement, or which workflow failures create support burden in strategic segments.
A disciplined metrics and reporting practice for product teams helps turn those operating signals into decisions leadership can use.
If a metric can't influence prioritization, staffing, or investment, it probably belongs in a team dashboard, not an executive one.
Common Failure Modes and How to Avoid Them
Most broken operations don't fail because people are careless. They fail because the designed process only works under normal conditions.
That's the flaw behind a lot of polished process diagrams. They assume clean inputs, clear ownership, and predictable exceptions. Real SaaS work rarely looks like that. A high-value customer reports a bug that can't be reproduced. A feature request arrives bundled with a renewal threat. Engineering discovers the fastest workaround creates long-term maintenance debt. The nominal process stops helping right when the stakes rise.
Guidance on operations often misses this practical layer. One of the biggest gaps is exception handling. Generic process explanations usually don't tell teams what to do when constraints make the standard path unworkable, or when the right answer is to redesign the operation instead of forcing it, a gap highlighted in this discussion of real-world operational trade-offs.
Silo syndrome
A familiar failure mode is the split between support, success, product, and engineering.
Support sees pain first but logs it as isolated tickets. Success hears renewal risk but keeps it inside account plans. Product gets a filtered summary. Engineering receives a Jira issue with none of the commercial context. By the time work is prioritized, the original signal has been stripped of urgency and nuance.
Fix it by defining a common evidence packet for important work. That packet should carry user context, affected workflow, business impact, and confidence level. If those fields don't travel together, teams will keep debating from partial information.
Metric myopia
Some teams do measure operations. They just measure the wrong thing.
If the primary target is “close more tickets,” support may optimize for speed over signal quality. If product is rewarded for release count, teams may split work into smaller launches without improving outcomes. If engineering is judged only on throughput, reliability and maintainability can gradually erode.
Use a balanced view. Delivery speed matters. So do quality, recurrence, and business effect.
Tooling sprawl
Tooling sprawl creates a false sense of maturity. More systems can make a weak process look complex.
A typical pattern is this: support data in Zendesk, account notes in Salesforce, product usage in Mixpanel or Amplitude, bugs in Jira, call transcripts in another tool, and ad hoc prioritization in a spreadsheet. Nothing is technically missing. The problem is that nobody can see the whole picture at decision time.
A disconnected stack doesn't just slow work. It changes which work gets chosen, because only the easiest evidence is visible.
No path for exceptions
The most expensive operating failures usually come from edge cases.
You need explicit rules for questions like these:
- Escalation rules. When does a customer-specific issue become a product-level priority?
- Redesign triggers. When does repeated workaround effort mean the workflow itself should be changed?
- Temporary decisions. Who can approve a short-term fix when the ideal solution won't land in time?
- Communication ownership. Who tells sales, support, and customers what's happening while the issue is in flight?
If your process can only handle the happy path, it isn't operational. It's aspirational.
How to Turn Customer Feedback Into Prioritized Work
Customer feedback becomes useless the moment it turns into a popularity contest.
The teams that handle feedback well don't just collect it. They operationalize it. They define how signals enter the system, how they get synthesized, how they're scored, and how decisions come back out in a form engineering, product, support, and revenue teams can use.
Start with one intake layer
Feedback is usually scattered across support tickets, chat transcripts, call recordings, CRM notes, survey comments, and usage analytics. Pulling all of that into one place is the first operational win.
This doesn't mean every note gets equal weight. It means every note enters the same system with consistent labels. Capture who reported it, what workflow is affected, whether it signals a bug or unmet need, and what account context matters. Teams that need a starting framework for streamlining customer feedback processes often benefit from a structured review template before they automate anything.
Define the workflow before adding automation
Process discipline is essential. Process design is the act of defining how work flows through a system, and stronger design reduces variability and creates a stable baseline for automation because the process is specified before tools are introduced, as described in this explanation of process design in operations management.
In practice, that means agreeing on the path:
- Capture feedback from every meaningful source.
- Normalize the language so duplicate issues can be grouped.
- Synthesize recurring themes across accounts and channels.
- Assess impact using account value, segment importance, severity, and usage context.
- Prioritize with clear decision rules, not loud internal lobbying.
- Route into Jira, Linear, or the engineering planning process.
- Close the loop with internal teams and customers.
That operating sequence matters more than the choice of tool.
Move from comments to patterns
Raw feedback is qualitative. Prioritization cannot stay qualitative forever.
Once data is centralized, the next task is pattern detection. You're looking for repeated friction in the same workflow, repeated requests from the same segment, or a bug that appears small in support volume but is concentrated in strategically important accounts. Manual spreadsheets usually collapse here. They can store notes, but they don't surface compound patterns well.
A useful guide to analyzing customer feedback for product decisions can help teams build this layer more intentionally.
Attach business impact before roadmap debate
A recurring mistake is discussing “importance” before quantifying what's at stake.
The better sequence is to estimate impact first. Ask which accounts are affected, whether the issue appears in renewal conversations, whether it blocks expansion, whether it interrupts onboarding, and whether usage data supports the complaint. Even when you can't assign a precise number, you can still classify work by commercial significance.
This is the point where product intelligence platforms become useful. A tool like SigOS can ingest support tickets, chat transcripts, sales calls, and usage data, then help teams identify recurring themes and connect them to churn, expansion, and revenue impact. That doesn't replace judgment. It gives judgment a stronger evidence base.
Here's a walkthrough format that many teams find useful once they're building this discipline into daily work:
Prioritize by outcome, not volume
The highest-volume request isn't always the highest-value one.
A small workflow issue affecting key accounts can matter more than a broad but low-consequence annoyance. Likewise, a feature request from a flagship prospect may matter, but only if the request fits the product strategy and the implementation cost doesn't distort the roadmap. Good operations makes these trade-offs visible instead of political.
Use a short decision table:
| Question | Why it matters |
|---|---|
| Does this affect retention? | Protects existing revenue and customer trust |
| Does it unlock expansion or unblock sales? | Connects product work to growth |
| Is the issue repeated across sources? | Reduces bias from one-off anecdotes |
| Is there a workaround? | Helps separate urgent work from painful but manageable friction |
| What is the delivery cost? | Prevents expensive distractions from dominating |
The best prioritization systems don't remove debate. They make the debate evidence-based.
Close the loop fast
A process of operations is incomplete if communication stops after prioritization.
Support needs to know what changed so ticket handling improves. Success needs language for customer follow-up. Sales needs realistic guidance on roadmap commitments. Product and engineering need to know whether the shipped fix reduced the original pain.
That final loop is where feedback stops being a pile of requests and starts becoming an operating asset.
Your Implementation Roadmap to Better Operations
Teams often don't need a full operational reset. They need one workflow that works well enough to prove the model.
Start with something painful and visible, usually bug triage, escalation management, or feature request intake from support and success. Build discipline there first. Then expand.
Step 1 and Step 2
Begin by mapping your current state. List every place customer feedback, reliability issues, and prioritization inputs currently live. Trace how a request moves from first signal to shipped work. Hidden delays and ownership gaps often surface within a single working session.
Then define ownership. Every stage needs a named operator. Someone owns intake quality. Someone owns synthesis. Someone owns commercial context. Someone owns prioritization decisions. If ownership is collective, it usually means ownership is absent.
Step 3 and Step 4
Pick a small set of north-star process metrics. Keep them tight. Choose measures that tell you whether the system is faster, more reliable, and more commercially aligned. Don't flood the team with dashboards on day one.
Then implement a unified feedback workflow. That can be built with your existing stack if the process is clear. If your team needs outside help thinking through operating design, Workflow consulting for scaling companies can be useful as a specialist input when internal teams are too close to the problem.
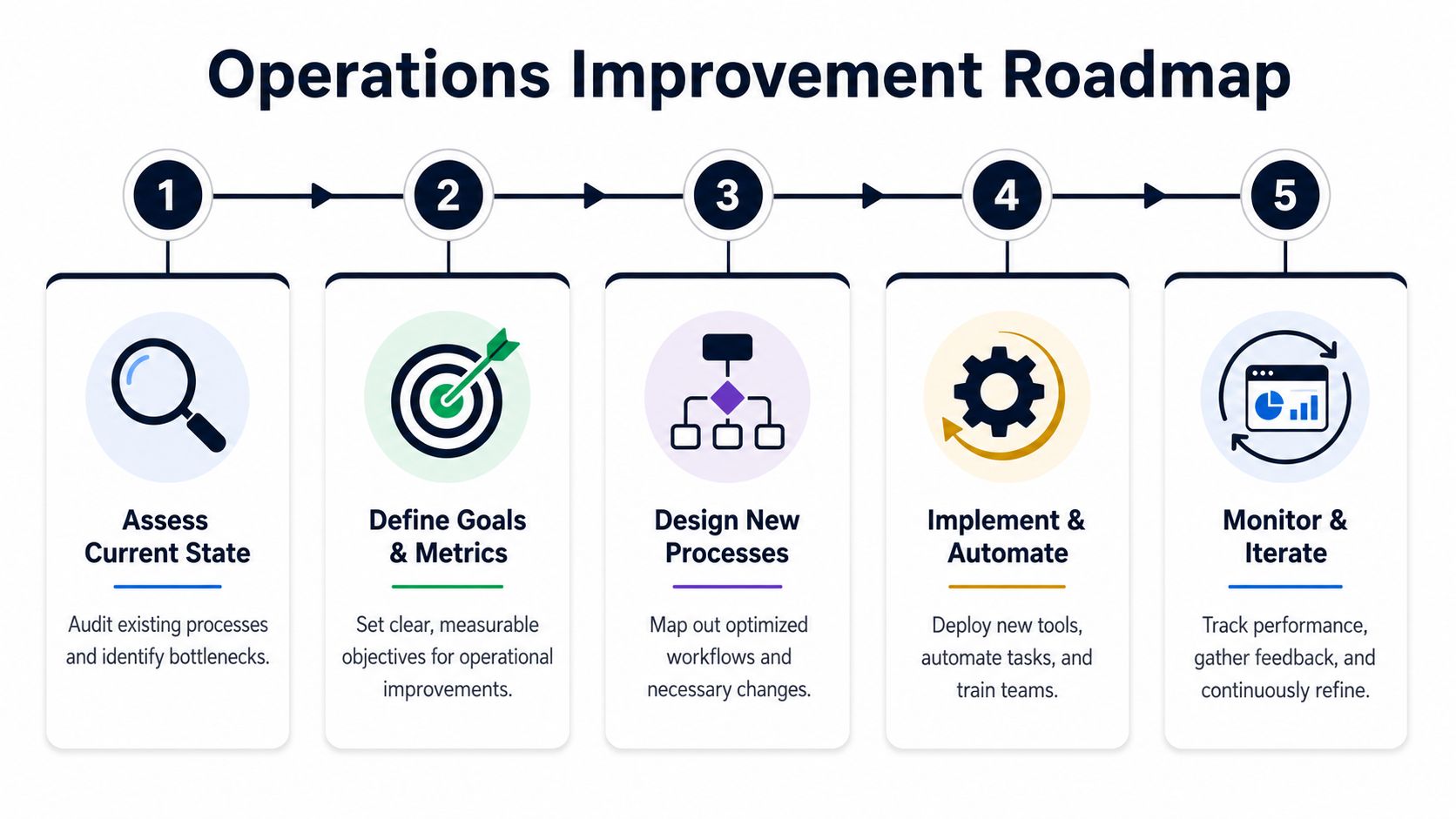
Step 5 and the ongoing cadence
Review the process on a schedule. Not just the output. The process itself.
Ask:
- Where did signals arrive too late. That usually points to broken intake or weak monitoring.
- Where did decisions stall. That often means unclear ownership or missing business context.
- Where did shipped work fail to change outcomes. That can indicate poor problem definition.
- Where are teams still using manual workarounds. Those are candidates for redesign or automation.
A practical technology roadmap template for operational planning can help align tooling, ownership, and timing without turning the effort into a giant transformation project.
The key is to start small and stay rigorous. One working feedback-to-priority pipeline will teach your organization more than six months of abstract process debates.
If your team is trying to connect customer feedback, product decisions, and revenue outcomes in one operating loop, SigOS is built for that job. It helps product, support, and growth teams turn scattered feedback into prioritized work by surfacing patterns across tickets, calls, chats, and usage data, then tying those patterns to churn, expansion, and commercial impact.
Keep Reading
More insights from our blog



Ready to find your hidden revenue leaks?
Start analyzing your customer feedback and discover insights that drive revenue.
Start Free Trial →