RICE Prioritization Framework: Guide to Data Roadmaps
Learn the RICE Prioritization Framework to build data-driven roadmaps effectively in 2026. Optimize product development and focus on key impact.

Your backlog probably looks familiar. Sales wants the enterprise feature that could secure a deal. Support wants the bug fix that keeps resurfacing in tickets. Design wants to clean up a flow that everyone knows is clunky. Engineering wants to pay down debt before the next release gets harder to ship.
A common pitfall for teams is not a shortage of ideas. Instead, they falter because every idea arrives with a different kind of pressure attached to it. The roadmap turns into a negotiation, and the loudest voice often wins.
That's exactly where the RICE prioritization framework helps. It gives product teams a way to compare unlike things with a shared scoring model, so roadmap decisions stop feeling arbitrary and start feeling defensible.
From Chaos to Clarity The Prioritization Problem
A common pattern shows up when teams outgrow founder-led prioritization. Requests pile up from every direction, each one urgent for a different reason. A strategic prospect needs a feature before renewal. A customer success lead is worried about repeated complaints. A VP wants a visible win this quarter. Product managers end up mediating urgency instead of evaluating value.
The result is predictable. Teams commit to work they can explain politically, not always work they can justify operationally. That's the HiPPO problem in practice. The highest paid person's opinion becomes the default scoring system.
RICE gives teams a calmer operating model. Instead of asking, “Who wants this most?” it asks four better questions: how many people will this reach, how much will it matter, how sure are we, and what will it cost to build? That shift matters because it forces trade-offs into the open.
What chaos looks like in real teams
You see it when roadmap reviews become storytelling contests. One stakeholder brings a painful anecdote from a single customer. Another brings conviction but no evidence. A third argues from strategy, but the team has no mechanism for comparing strategic importance against delivery cost.
That's usually a signal that the scoring system is hidden in people's heads. Once teams make criteria explicit, prioritization improves fast. The same discipline also helps improve R&D knowledge management, because decisions stop disappearing into meeting notes and start becoming reusable operating logic.
Practical rule: If your team can't explain why item three is above item seven without referring to personalities, you don't have prioritization. You have politics.
A structured framework also makes roadmap conversations easier across functions. Engineering can challenge effort assumptions. Growth can challenge reach assumptions. Customer-facing teams can pressure-test impact. That kind of shared language is what turns a wishlist into a plan. If you're tightening the broader process, this guide to product roadmap development is a useful companion.
Deconstructing the RICE Formula
Intercom introduced the framework in 2013 in its post on RICE prioritization for product managers. The formula is simple:
RICE = (Reach × Impact × Confidence) / Effort
The value of the framework isn't the math itself. It's the discipline the math imposes. Each variable forces the team to define what it means before scoring starts.
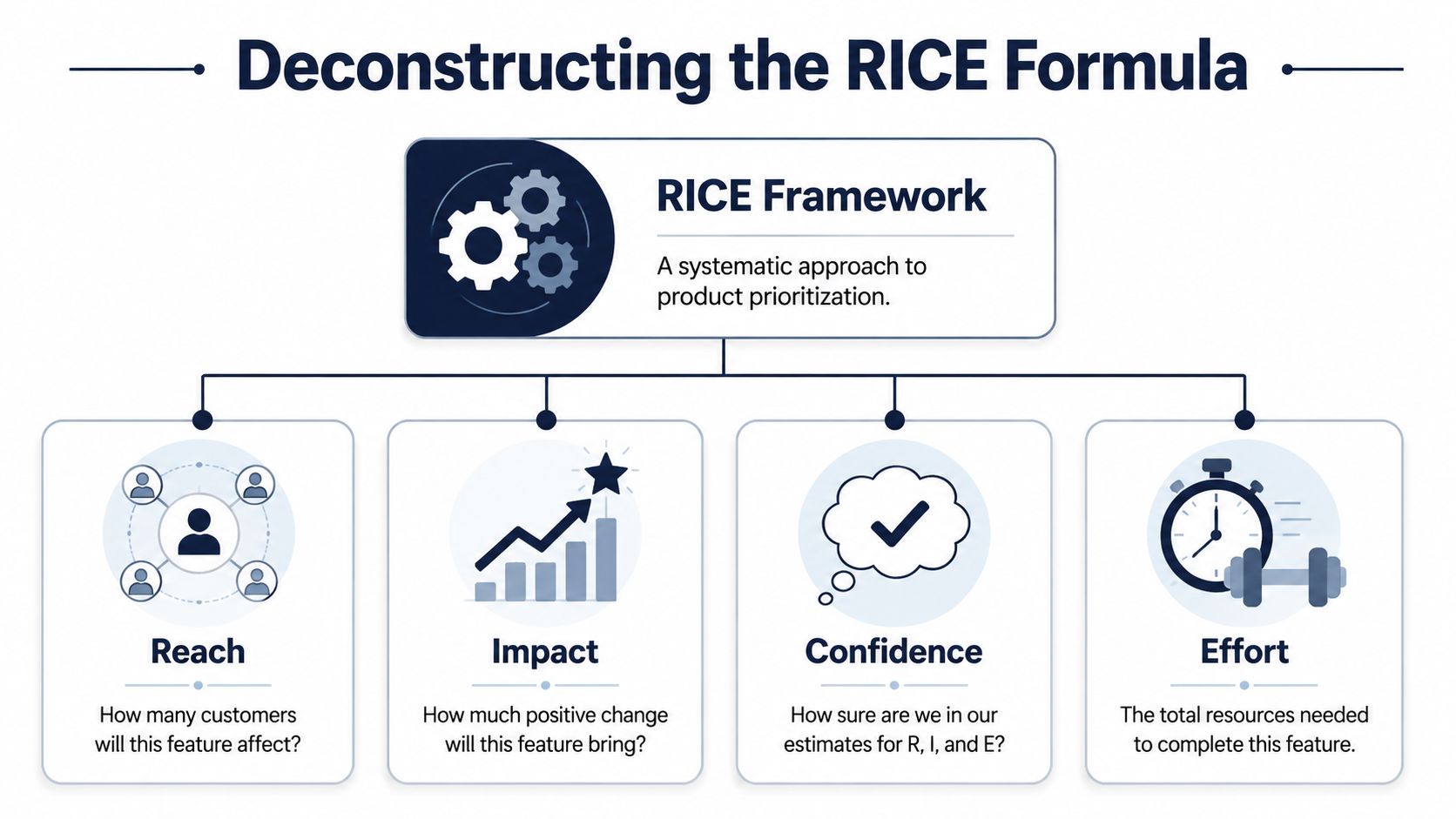
Reach
Reach answers the most basic question: how many people will this affect in a defined time period?
That time period matters. If one team scores reach over a month and another scores it over a quarter, the comparison breaks immediately. Good teams set a standard window and stick to it. In practice, reach works best when it's tied to a concrete unit such as users, accounts, transactions, or conversions.
Reach is where many teams drift into hand-waving. “A lot of users” isn't a score. “Most trial users” isn't a score either. You want a countable audience, even if it's directional.
Impact
Impact asks how much the feature changes the experience for each person it reaches. Intercom's model uses a fixed multiplier scale:
- Massive: 3x
- High: 2x
- Medium: 1x
- Low: 0.5x
- Minimal: 0.25x
This is the most judgment-heavy part of the formula, so teams need a rubric. Without one, “high impact” starts meaning “I care about it.” The best approach is to define impact in business terms. For one team, that might mean activation. For another, retention, expansion potential, or support burden reduction.
Confidence
Confidence is the correction factor. It prevents teams from pretending weak assumptions are solid evidence. The standard percentages are:
- High confidence: 100%
- Medium confidence: 80%
- Low confidence: 50%
Experienced product leaders save teams from their own enthusiasm. If reach is estimated from product analytics but impact is based on a few anecdotal calls, confidence shouldn't be maxed out. The score needs to reflect uncertainty.
Confidence doesn't punish ambition. It punishes pretending.
Effort
Effort is the denominator for a reason. Great ideas still lose priority when they consume too much capacity relative to their expected return.
RICE typically measures effort in person-months. That keeps estimation grounded at the delivery level rather than in abstract story points that don't translate well outside engineering. Effort should include design, engineering, data work, testing, release coordination, and any meaningful follow-on operational load.
A practical mistake is treating effort as engineering time only. Product teams pay for complexity long after code ships. If support, onboarding, compliance, or analytics work expands meaningfully, that belongs in the estimate.
What the score really means
A RICE score doesn't tell you what to build in isolation. It tells you which item delivers the most total impact per time worked under a shared scoring model. That's what makes the framework useful. It turns roadmap debate into a series of assumptions your team can inspect, challenge, and improve.
Putting RICE to Work A Worked Example
Teams usually understand RICE once they score two features side by side. The contrast is what makes the framework useful.
Take a common product decision. One proposal is Redesign Onboarding Flow. The other is Add SAML Integration. Both matter. The question is which deserves the next slot on the roadmap.
Start with a simple comparison.

Feature A redesign onboarding flow
The onboarding redesign usually has broad exposure. New users hit it immediately, and if the current path is leaky, a cleaner flow can improve early activation across a wide slice of traffic.
A team might score it like this:
| Component | Score | Why |
|---|---|---|
| Reach | 8,000 | New users and invited teammates touch the flow in the scoring period |
| Impact | 2x | Better activation matters, but it may not transform every account equally |
| Confidence | 80% | Analytics show drop-off points, but the exact lift is still an estimate |
| Effort | 4 | Design, frontend work, instrumentation, QA, and rollout coordination |
The score is:
(8,000 × 2 × 0.8) / 4 = 3,200
That's a strong candidate because it touches many users, and the team has decent evidence that the current flow underperforms.
Feature B add SAML integration
SAML has narrower reach in most SaaS products, but the impact on the right accounts can be dramatic. Enterprise buyers often treat it as a requirement, not a nice-to-have.
A team could score it like this:
| Component | Score | Why |
|---|---|---|
| Reach | 400 | Only a subset of accounts need it in the scoring period |
| Impact | 3x | For security-conscious buyers, this can decide whether a deal moves forward |
| Confidence | 50% | The request is strong, but the team lacks broad validation beyond sales conversations |
| Effort | 2 | Implementation is meaningful but bounded |
The score is:
(400 × 3 × 0.5) / 2 = 300
That doesn't mean SAML is unimportant. It means that in a pure RICE comparison, onboarding creates more expected return per unit of effort during the chosen period.
The score is the start of the conversation, not the end. Enterprise blockers, compliance commitments, or strategic account pressure can still justify taking the lower-scoring item first.
That's where many teams go wrong. They either worship the score or ignore it. Strong operators do neither. They use RICE to make trade-offs visible, then layer in strategic context openly rather than hiding it.
A short walkthrough helps if you want to see another take on applying the method in practice.
What this example teaches
The worked example exposes three realities that show up in almost every backlog review:
- Broad reach often beats concentrated urgency. A feature that improves a core flow for many users can outscore a highly requested edge-case feature.
- Confidence matters more than optimistic teams think. If the evidence is thin, the framework should discount the score.
- Low effort provides a significant advantage. Some ideas win because they're cheap enough to produce a strong return even with moderate impact.
That last point is why RICE works especially well for teams balancing growth bets, customer requests, and platform improvements in the same queue.
Why RICE Wins for Data-Driven Teams
RICE changes team behavior because it replaces opinion with a scoring language that everyone can inspect. That matters more than the formula itself. When product, engineering, support, and go-to-market teams are all using the same inputs, disagreement becomes useful instead of political.
The strongest case for RICE is that it helps teams escape instinct-driven prioritization. According to Atlassian's overview of product prioritization frameworks, analysis shows RICE can reduce prioritization bias by over 70% compared with HiPPO-style decisions, while teams using its structure reported a 30% increase in feature delivery speed and a 25% reduction in churn risks associated with delayed high-impact work.
It forces sharper thinking
Teams can't hide behind vague arguments when they need to score reach in concrete units and effort in person-months. Someone has to define who is affected. Someone has to say how much it matters. Someone has to admit how certain or uncertain the evidence really is.
That's healthy pressure. It exposes weak reasoning early, before work turns into roadmap debt.
It improves alignment without pretending everyone agrees
RICE doesn't eliminate conflict. It upgrades the quality of conflict.
Instead of hearing “sales keeps hijacking the roadmap” or “product doesn't understand customer pain,” teams can debate specific assumptions. Is the reach estimate too broad? Is the impact inflated? Is the confidence unjustified? Those are solvable arguments.
It creates a record of why decisions happened
This is one of the most underrated benefits. Six weeks after a planning decision, teams can go back and inspect the logic. If they were wrong, they can see where. Maybe they overestimated reach. Maybe they underestimated effort. Maybe confidence should have been lower.
That feedback loop is what makes RICE valuable over time. The framework becomes more accurate as the organization gets better at estimating and learning, not just better at arguing.
Comparing RICE with Other Prioritization Frameworks
A good product team shouldn't be loyal to one framework. Different planning problems need different tools. RICE is powerful, but it isn't the answer to every decision.
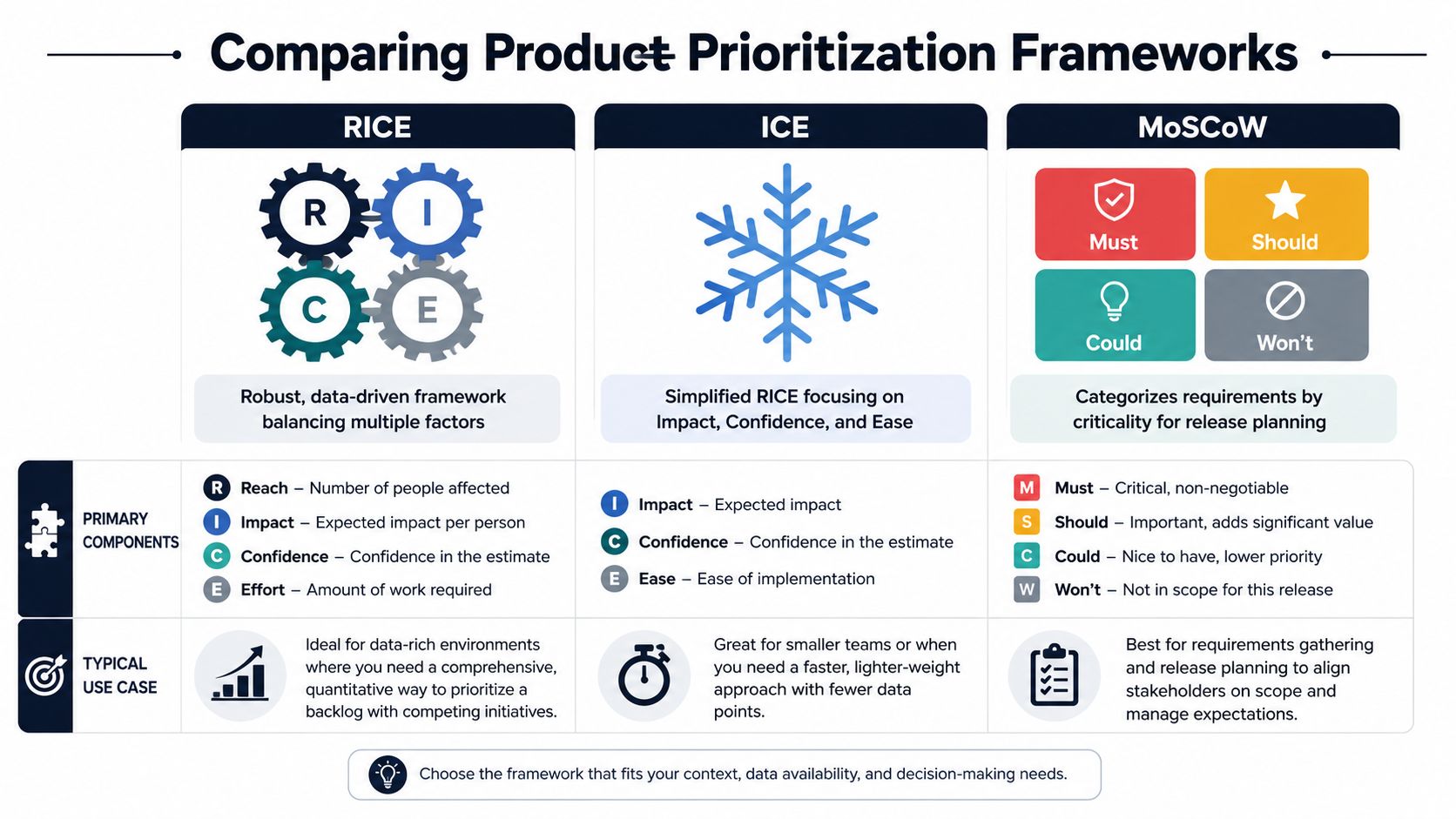
Where RICE fits best
Use RICE when you need to compare many backlog items that compete for the same capacity and you want a clear view of expected return versus effort. It's especially useful when requests come from multiple channels and the team needs a common operating model.
RICE works best when you have at least some usable data. If your team can estimate audience size, define expected business effect, and size delivery work reasonably well, the framework stays grounded.
Where ICE is simpler
ICE strips the model down to Impact, Confidence, and Ease. That makes it faster to run, which is useful for small teams or early-stage products moving through ideas quickly.
The trade-off is precision. Without a separate reach variable, a feature that helps a tiny group a lot can look similar to a feature that helps a broad segment moderately. If that distinction matters, RICE is usually the better choice.
Where MoSCoW helps more
MoSCoW groups work into Must have, Should have, Could have, and Won't have. That makes it useful for release planning, especially when deadlines are fixed and the team needs scope control more than score optimization.
MoSCoW is less effective when every stakeholder thinks their request belongs in “Must.” It can also flatten nuance. Two “Should” items may be very different in value and effort, but the framework won't tell you that on its own.
Kano solves a different problem
Kano is useful when the team is trying to understand how features affect satisfaction. Some capabilities are basic expectations. Others create delight. Some barely matter at all.
That's not the same question RICE answers. Kano helps you understand perception and expectation. RICE helps you decide what to do next when capacity is limited.
| Framework | Best for | Main strength | Main limitation |
|---|---|---|---|
| RICE | Backlog ranking across mixed initiatives | Balances value, certainty, and delivery cost | Depends on input quality |
| ICE | Fast prioritization with lighter process | Quick and simple | Reach can get lost |
| MoSCoW | Release scoping under fixed timelines | Strong for scope negotiation | Categories can become subjective |
| Kano | Understanding customer satisfaction drivers | Great for product discovery | Doesn't rank effort-adjusted delivery priorities well |
If you work across different planning environments, this prioritization guide for Google Workspace users offers a practical look at how teams adapt methods to real workflows. For a deeper look at backlog operating models, this piece on backlog prioritization techniques is also worth reviewing.
Common Pitfalls When Using RICE and How to Avoid Them
Most failures with the RICE prioritization framework don't come from the formula. They come from how teams use it.
Garbage in garbage out
If reach is a guess, impact is inflated, and effort excludes half the work, the score is nonsense. Teams sometimes blame the framework when the issue is undisciplined inputs.
Fix that by creating a scoring rubric. Define what counts as high impact in your business. Define the time window for reach. Define what must be included in effort. Once those rules exist, scores become comparable.
Analysis paralysis
Some teams overcorrect and wait for perfect data. They stall planning because every variable feels debatable.
Don't do that. Time-box the scoring session. Use the best evidence available, mark confidence accurately, and move forward. RICE is designed to handle uncertainty. That's what the confidence factor is for.
Field note: A rough score with explicit assumptions is more useful than a perfect-looking score that took too long to matter.
Hidden subjectivity in impact
Impact is where personal preference sneaks back in. A PM may overvalue workflow polish. Sales may overvalue prospect requests. Engineering may undervalue invisible customer friction because it doesn't look technically interesting.
The fix is to tie impact to business outcomes your team cares about. Activation, retention risk, expansion potential, workflow completion, or support burden are better anchors than personal enthusiasm.
Treating the score as law
This is the most dangerous mistake. RICE is a decision aid, not an autopilot.
A lower-scoring item can still be the right choice if it supports strategy, addresses compliance, protects a key account, or reduces a serious platform risk. The important thing is to override the score explicitly. Document why the exception exists so the team can learn from it later.
Operationalizing RICE with Product Intelligence
Manual RICE works. Spreadsheet RICE is better than political RICE. But modern teams usually need more than a quarterly scoring workshop.
The biggest upgrade is connecting each input to systems that already hold evidence. Reach can come from product analytics tools such as Mixpanel or Amplitude. Effort can come from Jira, Linear, or engineering planning rituals. Impact is the hard one, because it often lives across support tickets, call notes, CRM context, usage patterns, and churn signals.
That's where product intelligence changes the quality of the framework. Instead of estimating impact from a handful of anecdotes, teams can aggregate recurring feedback themes, tie them to account segments, and compare feature requests against actual commercial risk or expansion potential. The point isn't to remove judgment. It's to give judgment a stronger factual base.
A scalable setup also makes confidence easier to score accurately. If reach is sourced from analytics, effort from delivery systems, and impact from unified customer evidence, the team can distinguish between solid estimates and speculative bets much more clearly.
Teams moving in this direction usually benefit from stronger data access across functions. If you're building that capability, this guide to self-serve analytics for product teams is a practical place to start.
The primary shift is cultural. RICE stops being a static exercise and becomes a living decision system. Scores improve as customer evidence improves. Roadmaps become easier to defend because the assumptions behind them are visible, current, and tied to real behavior rather than whoever made the strongest argument in the room.
If you want to connect roadmap decisions to actual customer behavior and revenue signals, SigOS is built for that job. It helps teams turn noisy feedback from support, sales, and product usage into prioritized signals they can act on, so RICE scoring starts with evidence instead of guesswork.
Keep Reading
More insights from our blog

Ready to find your hidden revenue leaks?
Start analyzing your customer feedback and discover insights that drive revenue.
Start Free Trial →