Build a Weighted Scoring Model: AI for Prioritization
Learn to build an effective weighted scoring model. Our guide covers design, calibration, pitfalls, and using AI for data-driven prioritization in 2026.

Monday's roadmap meeting starts with confidence and ends in politics.
Sales wants the enterprise feature because a late-stage deal is blocked. Support wants the reliability work because ticket volume is rising. Customer success wants the onboarding fix because renewals feel shaky. Engineering wants to pay down infrastructure debt before another launch makes the stack harder to maintain. Everyone has a valid argument, and most of those arguments are backed by some kind of truth. The problem is that truth arrives in fragments.
Without a shared scoring system, teams usually default to status, urgency theater, or whichever narrative sounds most strategic in the moment. That's how product orgs end up with roadmaps that are hard to defend and even harder to revisit six months later.
A weighted scoring model fixes that. Not because it removes judgment, but because it forces judgment into the open. It gives teams a visible set of criteria, a clear way to express trade-offs, and a ranking method that can be audited instead of debated endlessly. Used well, it turns “I think this matters more” into “we agreed this criterion matters more, and here's how it affected the ranking.”
Most guides stop there. They explain the math, then wave at a workshop for assigning weights. That's where the core problem begins. In SaaS, priorities move faster than annual planning cycles. If your weights stay static while customer behavior shifts, your model becomes neat, clean, and wrong.
The End of Loudest Voice Prioritization
The failure pattern is familiar. A PM walks into planning with a backlog full of ideas, bug themes, customer requests, and technical initiatives. By the end of the meeting, the roadmap reflects stakeholder influence more than product strategy.
One executive pushes for an AI add-on because competitors are talking about AI. Another argues for workflow improvements because churn feedback mentioned usability. Support brings screenshots from frustrated users. Sales arrives with a list of “must-have” requests from prospects. Engineering points out that half the list is riskier than it looks.
Nobody is irrational. The process is.
What the loudest voice actually costs
When prioritization depends on persuasion, teams create three problems at once:
- Decisions become hard to repeat. If you rerun the meeting with a different cast, you often get a different roadmap.
- Trade-offs stay hidden. Teams argue about features instead of arguing about what matters most.
- Post-launch learning gets lost. Months later, nobody can explain why one initiative beat another.
That's why mature teams move toward a weighted scoring model. It doesn't eliminate disagreement. It channels disagreement into a structure that leadership, product, engineering, and revenue teams can all inspect.
A good prioritization method doesn't stop debate. It makes the debate explicit, bounded, and reusable.
The shift from opinion to evidence
The practical value of a weighted scoring model is simple. It lets a team compare unlike options on a common frame. A churn-reduction fix, an upsell feature, and a platform investment can sit in the same decision set if the criteria are clear enough.
That matters most when the roadmap carries competing goals. If you're balancing expansion, retention, operational drag, and delivery cost, gut feel won't hold up for long. You need a method that can show why one item ranks above another, and why that ranking changes when strategy changes.
Product teams begin to gain significant advantage. Once prioritization becomes visible, you can improve it. You can test whether your criteria reflect reality. You can challenge inflated scores. You can update weights when market conditions shift. And with better tooling, you can feed the model with live signals instead of waiting for quarterly opinion swaps.
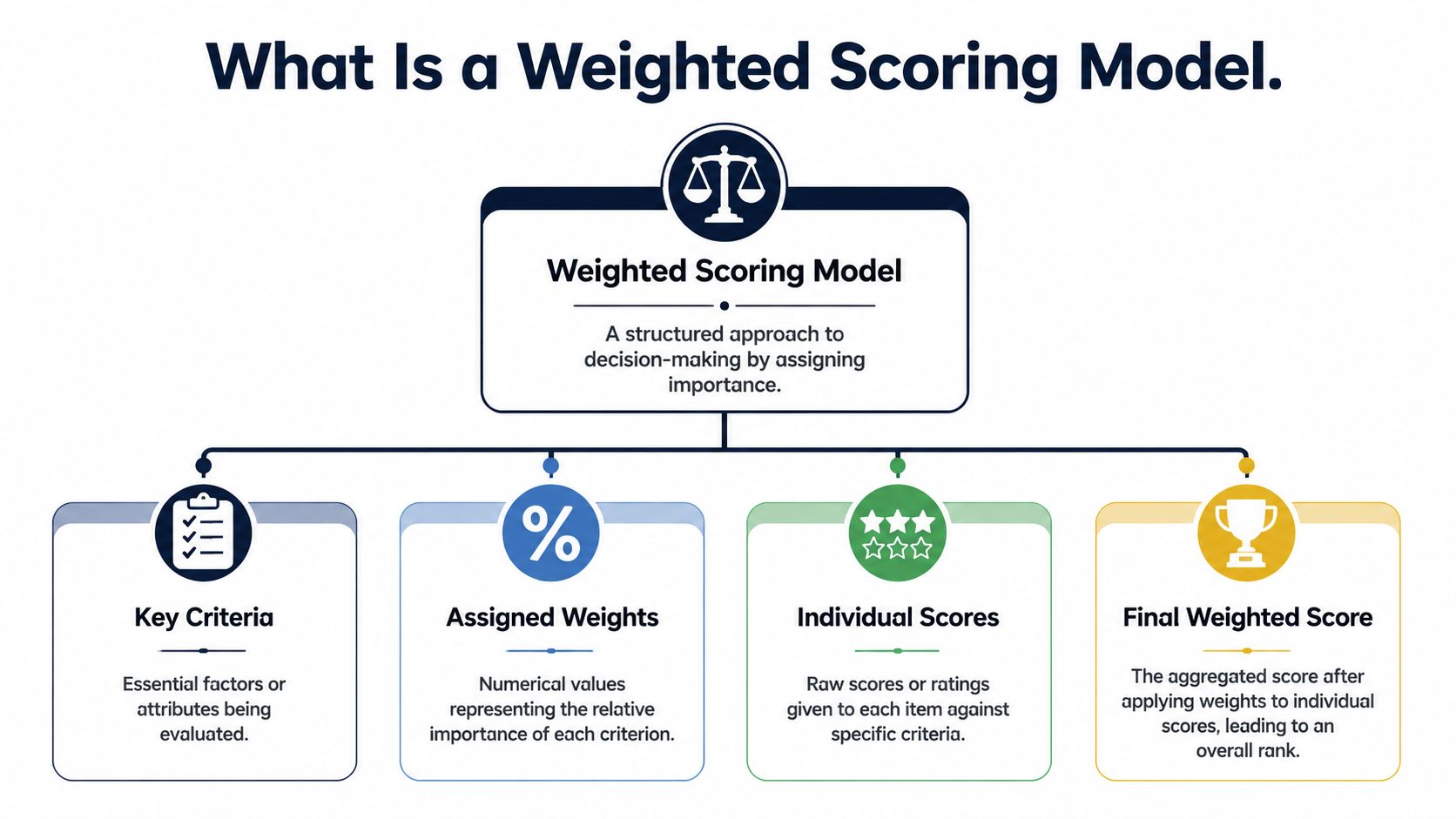
What Is a Weighted Scoring Model
Picture a judge's scorecard. In a diving competition, judges don't ask one vague question like “Was that dive good?” They score against specific dimensions. Some dimensions matter more than others. The final result comes from combining those judgments in a structured way.
A weighted scoring model works the same way for product decisions.
The three parts that matter
Every weighted scoring model has three basic inputs.
- Criteria are the dimensions you care about. In product work, that might include customer value, revenue impact, churn reduction, strategic fit, engineering effort, or delivery risk.
- Weights express relative importance. If churn reduction matters more than speed to market this quarter, it gets a higher weight.
- Scores rate how well each option performs against each criterion.
The output is a single composite score that lets you rank options side by side.
According to the Casebasix weighted scoring model framework, weighted scoring models were formalized as a practical multi-criteria decision method that converts qualitative and quantitative criteria into one ranked score by multiplying each criterion score by its assigned weight and summing the results. Modern guides typically use normalized weights that add up to 100%, with common scoring scales of 1 to 5 or 1 to 10.
How the math works without overcomplicating it
The formula is simple:
weighted score = sum of each criterion score × its weight
If a feature scores high on a heavily weighted criterion, that advantage matters more. If it scores well on something the team considers secondary, the lift is smaller.
Here's the logic in plain terms:
| Component | Question it answers | Example |
|---|---|---|
| Criteria | What matters? | Customer value, effort, strategic fit |
| Weight | How much does it matter? | Strategic fit matters more than ease of implementation |
| Score | How well does this option perform? | Feature A scores stronger on retention than Feature B |
Practical rule: If two teams can't explain why a criterion exists, it shouldn't be in the model.
Why teams trust the model
The weighted scoring model earns trust because it exposes assumptions. Instead of saying “enterprise customers are more important,” the team encodes that belief into a weight. Instead of vaguely claiming a feature is high impact, the team gives it a score against a defined criterion.
That doesn't make the model perfectly objective. It makes the subjectivity legible.
And that's the point. Product prioritization rarely fails because teams lack opinions. It fails because opinions aren't translated into a system that can be challenged, improved, and recalculated when the business changes.
Why and When to Use This Model for Prioritization
Some prioritization methods are useful because they're fast. Others are useful because they survive scrutiny. The weighted scoring model belongs in the second category.
If you're sorting a small list in a single team, simple frameworks can be enough. But once multiple functions are involved, simplicity starts hiding important trade-offs. A feature that looks urgent to sales may create outsized implementation cost. A reliability project that engineering sees as obvious may be invisible to leadership unless the model captures churn risk or customer pain.
Where simple methods fall short
Methods like MoSCoW, Kano, or rough impact-effort sorting work well for early filtering. They're lightweight and easy to facilitate. But they start to crack when you need to balance several strategic goals at once.
A weighted scoring model is more useful when you need to answer questions like these:
- Cross-functional conflict: How do we compare a support-driven fix with a sales-driven feature request?
- Portfolio complexity: How do we rank platform work, UX improvements, and revenue bets in one view?
- Executive scrutiny: How do we show why one initiative moved ahead of another?
As noted in the Tempo guide to weighted scoring models, an important feature of weighted scoring models is the standardization of decision factors into percentages and a single composite score. Many methods require all factor weights to total 100%, which makes the model transparent and auditable.
That auditable trail matters more than teams expect. It lets you revisit decisions without rebuilding the argument from memory.
Signals that you've outgrown ad hoc prioritization
You probably need a weighted scoring model if any of these sound familiar:
- Your roadmap meetings feel repetitive. The same arguments return every cycle.
- Your team serves several masters. Product, support, success, sales, and engineering all bring valid but conflicting priorities.
- Strategy changes faster than delivery. By the time you ship, the original rationale is already blurry.
- Leadership asks for defensibility. “Why this now?” becomes a standing question.
A lot of teams reach this point after trying lighter methods first. That's normal. Frameworks should match the complexity of the decision. If you want a broader view of how different methods fit different backlog situations, this guide to backlog prioritization techniques is a useful comparison.
What this model is especially good at
The weighted scoring model does three jobs well:
| Strength | Why it matters in practice |
|---|---|
| Strategic alignment | The team must say what matters most before ranking work |
| Decision traceability | You can inspect criteria, weights, and scores later |
| Stakeholder discipline | Discussion shifts from advocacy to trade-offs |
It's not the right tool for every choice. If you're making a quick binary decision with one dominant variable, this is overkill. But when the roadmap gets political, the model gives product leaders a way to make prioritization calm, explicit, and repeatable.
How to Design and Build Your Scoring Model
Most scoring models fail before anyone enters a score. They fail because the criteria are vague, the weights are political, or the scoring rubric leaves too much room for interpretation.
A strong model starts with strategy, not spreadsheets.
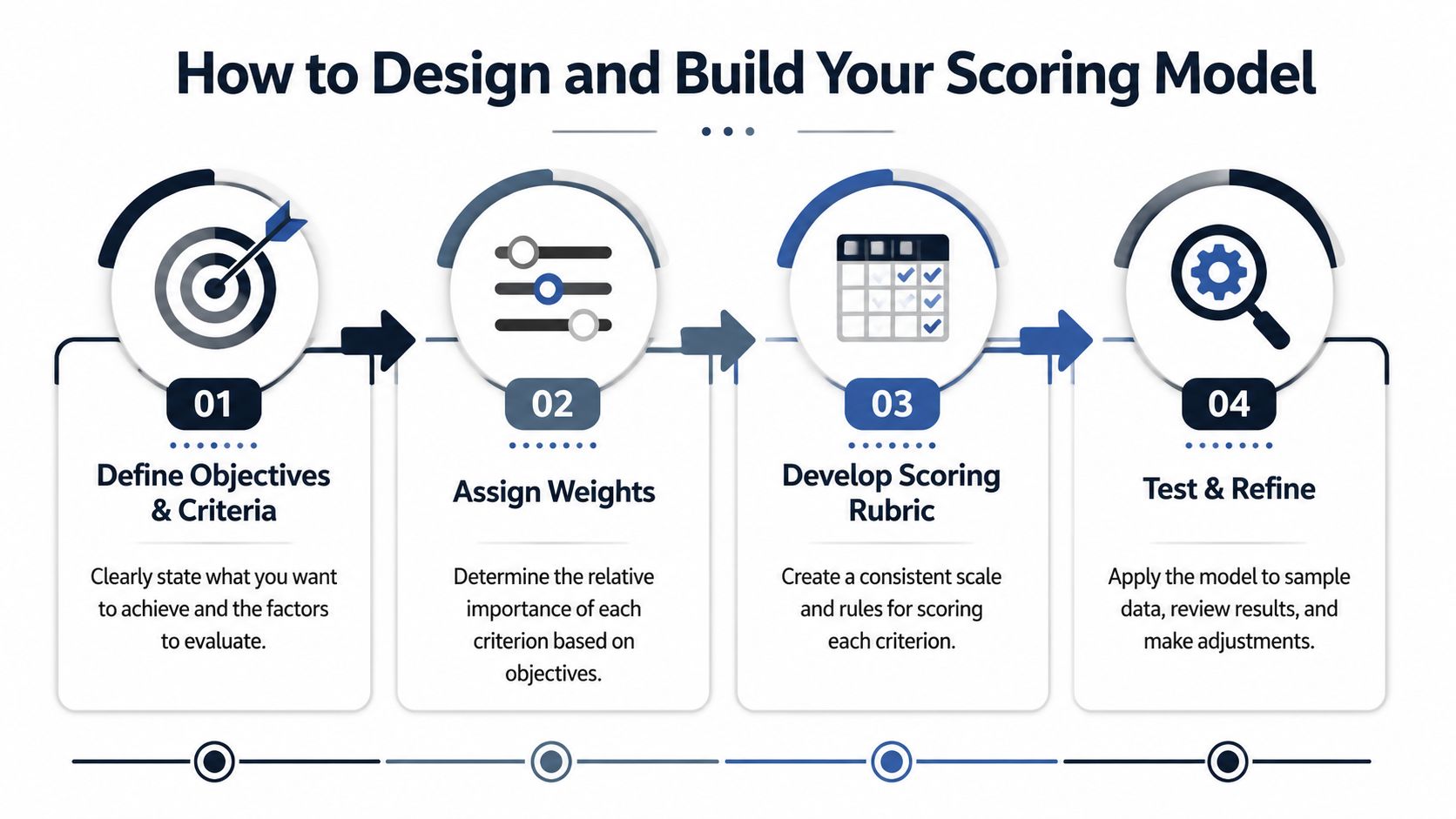
Start with the decision you're actually making
Before you define any criterion, narrow the frame. Are you prioritizing the next sprint, the next quarter, or the next roadmap cycle? Are you comparing features only, or also infrastructure and operational work?
If you mix radically different decision types without saying so, the model becomes noisy fast.
A clean starting point looks like this:
- Define the scope. Example: rank candidate initiatives for the next quarterly roadmap.
- Define the alternatives. Only include options that are realistic contenders.
- Define the business context. State the strategic priorities the model should reflect.
If the company is in a retention year, the model should say so. If enterprise expansion matters most, the model should say that too.
A lot of teams also benefit from a visual walkthrough before they build the spreadsheet. This short video is a useful primer on the mechanics:
Separate value from cost
This is one of the most important design choices. Don't lump all criteria into one flat list. Split them into benefit-oriented and cost-oriented dimensions.
According to the 6Sigma guide on weighted scoring prioritization, weighted scoring is most effective in product prioritization when criteria reflect both business value and delivery cost. The guidance recommends separating benefit-oriented criteria such as revenue impact or customer value from cost-oriented criteria such as effort or complexity, then assigning larger weights to strategic drivers.
That usually produces a more honest model.
Benefit-oriented criteria
These are the reasons to do the work.
- Customer value: Does this solve a meaningful problem for a meaningful segment?
- Retention impact: Is this likely to reduce reasons customers leave?
- Expansion potential: Could this enable upsell, cross-sell, or enterprise adoption?
- Strategic fit: Does this support the company's current direction?
Cost-oriented criteria
These are the reasons to delay, split, or reject the work.
- Engineering effort: How expensive is implementation?
- Complexity: How many unknowns or cross-team dependencies are involved?
- Risk: Could this create operational, security, or adoption problems?
- Time to value: How long before customers benefit?
If you want a practical companion for shaping these dimensions, a feature prioritization matrix can help teams pressure-test whether their criteria are balanced before they formalize weights.
Assign weights with structure, not rhetoric
At this juncture, teams often drift back into opinion.
Don't start with a group debate. Ask stakeholders to assign weights independently first. Then compare the spread. If one leader treats retention as dominant and another barely values it, that disagreement is useful. It means strategy is not as aligned as the roadmap document claims.
A workable process looks like this:
- Draft the criteria list first. Remove overlap before weighting starts.
- Ask each function to allocate weights privately. Product, engineering, support, success, and go-to-market should all participate if they shape the roadmap.
- Discuss outliers, not averages. The biggest gaps usually reveal the actual strategy questions.
- Lock weights before scoring options. Otherwise people unconsciously tilt the model toward favored initiatives.
Teams often think they have a feature debate. What they really have is a disagreement about what the business should optimize for.
Build a scoring rubric people can actually use
A scoring scale only works if each number means something. If one person uses a 5 to mean “important” and another uses a 5 to mean “transformational,” the model looks precise while hiding inconsistency.
Use a consistent scale such as 1 to 5. Then define each level in plain language for each criterion. For example:
| Score | Revenue impact example | Effort example |
|---|---|---|
| 1 | Minimal or unclear commercial upside | Very high effort |
| 3 | Meaningful upside for a known segment | Moderate effort |
| 5 | Strong upside tied to strategic goals | Low effort |
The exact wording matters less than consistency. The rubric should reduce interpretation drift.
Test the model before you trust it
Run the model on a small sample of real initiatives. Then inspect the ranking.
Ask three questions:
- Does the winner make sense?
- Does the result expose any flawed criterion or overweighted factor?
- Would a small weight change flip the ranking in a way that feels wrong?
If the answers are uncomfortable, that's useful. The model is surfacing weaknesses before those weaknesses shape the roadmap.
A Worked Example and Prioritization Template
A weighted scoring model becomes real when you run the numbers on a decision everyone recognizes. Let's use a simple SaaS scenario. The team must choose among three roadmap candidates:
- Feature A: SSO Integration
- Feature B: Dashboard Revamp
- Feature C: AI Report Builder
The model uses five criteria. Three capture business upside. Two capture delivery cost and risk. The weights sum to 100%, which keeps the logic visible and easy to audit.
Example weighted scoring model
| Criterion | Weight | Feature A: SSO Integration (Score) | Feature B: Dashboard Revamp (Score) | Feature C: AI Report Builder (Score) |
|---|---|---|---|---|
| Expansion revenue potential | 30% | 4 | 3 | 5 |
| Churn reduction potential | 25% | 5 | 4 | 2 |
| Customer demand signal | 20% | 4 | 3 | 5 |
| Implementation effort | 15% | 3 | 4 | 2 |
| Delivery risk | 10% | 4 | 4 | 2 |
How the math plays out
Multiply each score by its weight, then sum the results.
| Feature | Weighted total |
|---|---|
| SSO Integration | 4.10 |
| Dashboard Revamp | 3.55 |
| AI Report Builder | 3.95 |
SSO Integration ranks first. It doesn't win because it scores highest on every line. It wins because it performs well on the highest-weighted criteria, especially churn reduction and expansion relevance, without collapsing on cost and risk.
The AI Report Builder looks exciting and scores strongly on expansion potential and demand signal. But the lower scores on churn reduction, effort, and delivery risk pull it below SSO. Dashboard Revamp is solid across the board, but it doesn't dominate where the model says the business cares most.
The point of the model isn't to reward the flashiest idea. It's to reward the idea that best fits your stated priorities.
What this template teaches
This example shows three practical truths.
- Balanced options often lose to strategically aligned ones. Dashboard Revamp is respectable, but “pretty good everywhere” doesn't always beat “strong where it counts.”
- Weights shape the decision more than scores do. If you changed the strategy and increased the weight on customer demand signal while lowering churn reduction, the ranking could shift.
- The model is a decision aid, not a law. If the top two options land close together, that's a cue for sensitivity testing and discussion.
For teams building their first version, keep the template simple. Start with a small set of initiatives, a clear rubric, and a limited number of criteria. Complexity should come later, after the team learns where disagreement resides.
Supercharge Your Model with AI-Driven Signals
A weighted scoring model is only as good as its inputs. That's the hard truth most templates avoid.
The spreadsheet can be elegant. The formula can be flawless. But if the scores come from stale anecdotes and the weights come from quarterly opinion battles, the output still drifts away from reality.
Recent industry analysis shows the scale of that problem. 68% of product teams revise their prioritization criteria at least three times a year, yet 92% of weighted scoring models remain static for 12+ months, leading to “weighting drift” that correlates with a 24% increase in churn for misaligned features.
What dynamic scoring looks like in practice
Instead of asking a PM to estimate “customer impact” from memory, modern teams can feed live signals into the model:
- Support tickets show recurring pain themes.
- Usage metrics reveal which workflows are sticky, broken, or ignored.
- Sales calls surface blocked deals and repeated objections.
- Customer success notes expose expansion friction and renewal risk.
That changes the quality of the discussion. A team no longer argues only from instinct. It can look at observed behavior and ask whether the current weights still reflect actual business pressure.
This is especially useful for criteria that are usually vague, such as strategic urgency, customer pain, or retention risk. Those don't need to remain hand-wavy if the underlying signals are accessible.
From static scorecard to living model
AI helps in two places.
First, it improves scoring by summarizing large volumes of qualitative and behavioral data into clearer evidence. Second, it improves weight calibration by showing when the business context has shifted enough to revisit the model.
That matters in SaaS because customer reality changes faster than planning cycles. A workflow that looked secondary last quarter may become critical if support demand spikes or high-value accounts repeatedly hit the same blocker.
If your team is trying to operationalize that kind of product intelligence, this article on AI for product development is a useful reference point.
One example in this category is SigOS, which ingests support tickets, chat transcripts, sales calls, and usage metrics so teams can connect prioritization inputs to churn, expansion, and revenue patterns. In practice, that means criteria like customer pain or revenue relevance can be informed by observed signals rather than a workshop alone.
A practical way to recalibrate weights
You don't need fully automated prioritization to get value here. Start with a recurring review process tied to live inputs.
Try this operating rhythm:
- Review criteria on a fixed cadence. Don't assume last quarter's model still reflects this quarter's business.
- Bring evidence by criterion. For example, retention-related criteria should include churn themes, support volume, and adoption friction.
- Separate signal from noise. Not every loud request reflects broad importance. Teams evaluating support workflows often benefit from broader tooling context, such as this guide to compare knowledge base platforms, because documentation quality can strongly shape ticket patterns and distort raw feedback volume.
- Adjust weights only when the evidence changes the strategic picture. Don't reweight every week just because a single customer shouted.
A living scoring model doesn't chase every signal. It updates when repeated signals show that the business is optimizing for the wrong thing.
That's the true upgrade. AI doesn't replace product judgment. It gives judgment a stronger substrate.
Common Pitfalls and How to Validate Your Model
The biggest risk with a weighted scoring model isn't bad math. It's false confidence.
A ranked list feels scientific, so teams stop questioning it. They treat the top score like a verdict instead of a hypothesis. That's where prioritization models become dangerous. They can make weak assumptions look disciplined.
According to a 2025 MIT Sloan study on AI-driven product intelligence, 75% of SaaS companies use weighted scoring, but only 12% can demonstrate a statistically significant correlation between their model's top-ranked features and actual revenue expansion or churn reduction.

The mistakes that quietly break the model
Most failures come from a short list of habits.
- Score inflation: Every sponsor argues their initiative deserves a high mark, so the model loses discrimination.
- Criterion overlap: Teams include customer value, user pain, and satisfaction lift as separate lines even though they measure similar things.
- Static weights: Strategy changes, but the model doesn't.
- Rubric drift: A 4 means one thing to product and another thing to engineering.
- Blind obedience: Leaders follow the ranking without checking whether the result still makes business sense.
None of these are exotic mistakes. They show up in mature organizations all the time.
How to validate whether your model works
Validation starts with a simple question: did the work your model ranked highly produce the outcomes the model implied?
That means treating the model as something testable.
Back-test against historical decisions
Take a prior roadmap cycle and reconstruct the scoring model that would have been used. Then compare the highly ranked items with what happened afterward.
Look for patterns like these:
| Validation question | What to inspect |
|---|---|
| Did top-ranked items influence retention? | Renewal themes, churn reasons, customer success notes |
| Did revenue-oriented bets expand accounts? | Expansion signals, enterprise adoption, deal progression |
| Did cost assumptions hold? | Delivery time, engineering load, support burden after launch |
You don't need perfect attribution to learn from this. You need enough evidence to see whether the model consistently overrates certain classes of work.
Run sensitivity analysis
Small changes shouldn't produce nonsense. If moving one weight slightly flips the winner every time, your model may be unstable or your options may be too close to separate cleanly.
This doesn't mean the framework failed. It means the team needs to acknowledge that the decision is sensitive to strategic assumptions.
If a ranking collapses under minor weight changes, the model is telling you the choice is fragile. Listen to that.
Audit your criteria quality
Ask these questions regularly:
- Is each criterion distinct?
- Can scorers explain what a high score means?
- Are we using evidence where evidence exists?
- Have we changed strategy without changing weights?
A strong weighted scoring model gets sharper over time because the team learns where its assumptions were weak.
What good validation changes
Validation makes the model more than a planning artifact. It turns it into an operating system for product judgment.
Teams that validate regularly do three things better:
- They stop overvaluing fashionable work.
- They catch stale weights before those weights shape another quarter.
- They connect prioritization to business outcomes instead of presentation quality.
That's the mature posture. Use the model to force clarity. Then test whether that clarity predicts anything useful.
If your team wants a weighted scoring model that's fed by real customer and revenue signals instead of static spreadsheets, SigOS is one option to evaluate. It helps product, support, and growth teams connect support tickets, sales calls, chat transcripts, and usage data to prioritization inputs so roadmap decisions can be recalibrated against live behavioral evidence.
Keep Reading
More insights from our blog


Ready to find your hidden revenue leaks?
Start analyzing your customer feedback and discover insights that drive revenue.
Start Free Trial →