Data Science vs. Statistics: Guide for SaaS Teams
Data science vs statistics: A practical comparison for SaaS teams. Understand key differences, hiring, and how to leverage both to drive revenue.

Your team already has the meeting on the calendar.
Product wants to know why adoption stalled on a recently launched workflow. Customer success has a list of accounts that sound unhappy. Support has hundreds of tickets tagged with the same broad complaint, but nobody agrees on whether it's one issue or five. Growth wants to know which signals predict expansion. Someone says, “We need a data scientist.” Someone else says, “No, we need a statistician first.”
That debate matters because these roles solve different business problems. If you choose wrong, you either get a polished model that can't support a high-stakes decision, or a rigorous analysis that never turns into a working system.
For SaaS teams, data science vs. statistics isn't an academic label fight. It affects hiring, roadmap prioritization, experiment design, and how quickly you can turn messy product data into decisions that hold up under pressure. It also affects whether your team can separate actual customer signals from the kind of noisy inputs that usually come from fragmented tracking, inconsistent tags, and disconnected systems. Teams wrestling with that problem should first tighten up their approach to product data quality.
The Right Tool for the Data Deluge
A common pattern in SaaS is simple. You have more data than clarity.
Usage events live in the warehouse. Support tickets sit in Zendesk. Call notes are trapped in Gong or another conversation tool. Product feedback arrives through sales, chat, and email. The company says it wants to be data-driven, but in practice the team is trying to make roadmap calls from a mix of anecdotes, dashboards, and partial analyses.

The tension usually shows up when the stakes rise. If you're deciding whether to roll back onboarding changes, reprice a plan, or prioritize a bug affecting enterprise accounts, “the data suggests” isn't enough. You need to know whether the pattern is real, whether it generalizes, and whether someone can operationalize it.
The planning meeting where the roles get confused
In such situations, teams often blur disciplines.
A product manager asks for a churn model. What they need might be a careful test of whether a specific onboarding step causes lower retention. A customer success leader asks for proof that feature usage predicts renewals. What they may really need is a production pipeline that refreshes account risk signals every day. The request sounds similar. The work is not.
What changes when you frame it correctly
Once you define the business decision, the role becomes clearer:
- If the question is causal, statistics usually leads.
- If the question is operational, data science usually leads.
- If the question is both strategic and scalable, you need both.
The fastest way to waste a quarter is to use predictive tooling to answer an inferential question, or to use a one-off statistical analysis for a workflow that needs to run every day.
That's the practical frame for the rest of this article.
Defining the Disciplines by Business Value
The cleanest way to separate data science vs. statistics is by the kind of value each discipline creates inside a business.
Statistics helps a company prove something with rigor. Data science helps a company build something that runs.
Statistics helps you prove
In a SaaS setting, statistics is the discipline you lean on when leadership needs defensible answers. Did the pricing test change conversion? Did the new onboarding sequence reduce churn risk? Is a difference in activation meaningful, or just random movement in a small sample?
A strong statistician cares about assumptions, sampling, uncertainty, and experimental design. They're not just summarizing a chart. They're testing whether the signal holds up when you account for noise, bias, and model structure.
That's why statistics is often the right tool when the cost of a wrong answer is high. If the result will influence pricing, packaging, resource allocation, or a board-level narrative, you want inferential discipline before you move.
Data science helps you build
Data science starts with the same mathematical backbone but expands into software, machine learning, and data systems. The field wasn't coined as a new label for statistics. The term “data science” was created in the early 1960s, and by 2008 the title “data scientist” had become a buzzword, while statistics remained the older discipline and the methodological core of the broader field, as outlined in this history of data science.
For business teams, that historical shift matters because the work expanded. Modern data science includes computer science, machine learning, and data engineering alongside statistical reasoning. The job isn't only to estimate and validate. It's also to ingest data, transform it, train models, deploy workflows, and keep those workflows useful.
A simple business test
Use this test when the distinction feels fuzzy:
- Need confidence in a conclusion? You're asking for statistics.
- Need a repeatable system? You're asking for data science.
- Need both confidence and a system? Start with statistical rigor, then move into data science execution.
Practical rule: Statistics tells you whether to trust the signal. Data science turns that signal into something a team can use every day.
For product managers, this is the difference between an analysis deck and a live prioritization engine. Both can be valuable. They just solve different problems.
Comparing Core Philosophies and Methods
The distinction between data science vs. statistics isn't just tool choice. It's what each discipline treats as success.
Statistics is usually judged by inferential quality. Data science is usually judged by predictive and operational performance. That split affects how each side thinks about models, data, and business decisions, as described in this discussion of statistical foundations in data science.

Side by side view
| Criterion | Statistics | Data Science |
|---|---|---|
| Primary goal | Explain relationships, estimate uncertainty, test hypotheses | Predict outcomes, automate decisions, operationalize insight |
| Core question | What happened, why did it happen, and how certain are we | What will happen next, and how do we use that answer in production |
| Modeling style | Assumption-driven and theory-led | Computational and system-oriented |
| Typical data posture | Carefully defined samples and controlled designs | Large, mixed, multi-source datasets |
| Success measure | Inferential quality and validity | Predictive usefulness and workflow performance |
| Typical business output | Experiment readout, causal estimate, validated conclusion | Scoring model, ranking system, automated alert, deployed pipeline |
Inference and prediction are not the same job
A statistician usually asks whether the observed pattern reflects something real in the population. They care about sampling bias, confounding, and whether the model assumptions fit the data well enough to support the conclusion.
A data scientist often asks whether the model performs well on unseen data and whether it can be integrated into a business process. They still use statistical methods, but they're more likely to accept a more complex or less interpretable model if it improves operational value.
Statistics asks, “Can we trust this conclusion?” Data science asks, “Can we use this reliably at scale?”
That distinction matters in product work. Suppose your team identifies that accounts using a certain workflow tend to renew more often. A statistician will probe whether that relationship survives proper controls. A data scientist will ask whether that signal can help rank accounts for customer success action.
For teams running experiments, the inferential side becomes especially important. If you need a refresher on test design and interpretation, this guide on hypothesis testing for product teams is a useful reference.
Methods reflect the philosophy
The workflows differ because the philosophies differ.
Statistics leans on:
- Experimental design
- Regression and model specification
- Hypothesis testing
- Uncertainty quantification
- Interpretation under explicit assumptions
Data science leans on:
- Data acquisition and transformation
- Feature engineering
- Machine learning workflows
- Scoring and ranking
- Deployment and monitoring
A product manager doesn't need to master every method. But they do need to know what kind of answer they're asking for. If you ask a data scientist to “prove” a feature caused retention improvement, you may get a model that predicts retention without establishing causality. If you ask a statistician to “build a churn system,” you may get a rigorous report that still leaves the team doing manual triage.
The short video below gives a useful high-level framing before you decide how to staff the problem.
Workflows Tools and Business Deliverables
Titles are one thing. Daily work is another.
If you're a product leader, you need to know what lands on your desk at the end of the project. The easiest way to understand data science vs. statistics is to compare the workflow each role typically follows and the deliverable each role tends to produce.
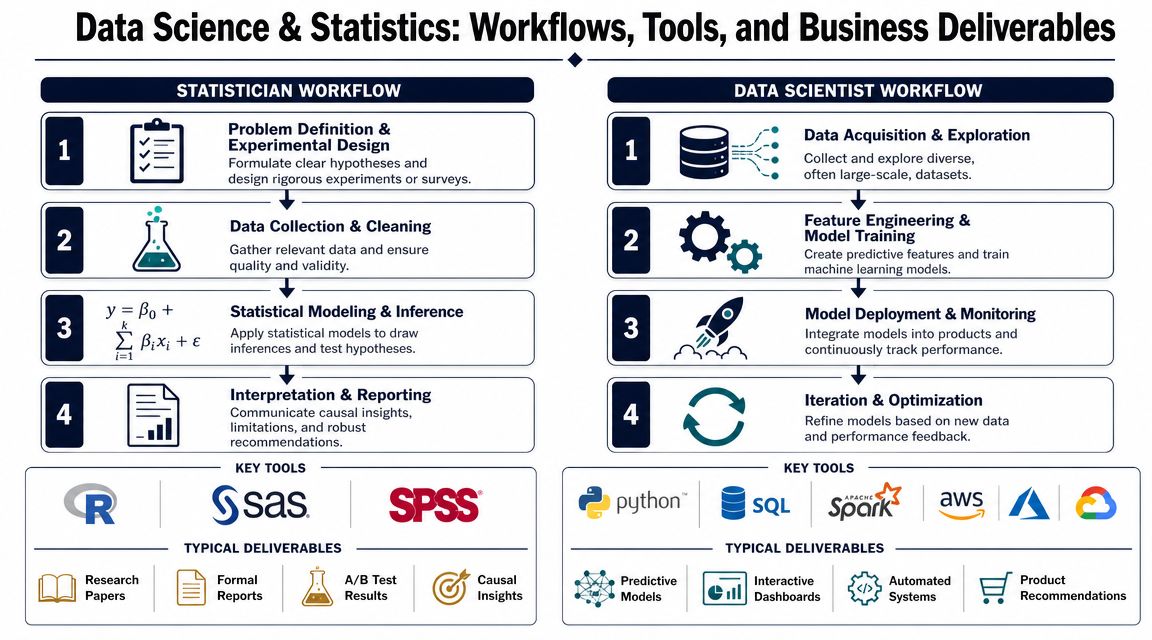
What a statistician usually delivers
A statistician's workflow is narrower, but that isn't a weakness. It's specialization.
They typically start with the business question and shape it into a formal analytical problem. Then they focus on study design, variable definition, sample quality, and the modeling approach needed to draw a defensible conclusion. Their tooling often reflects that emphasis. A practical distinction often cited is that data scientists are expected to know Python, R, or SQL and work with big data at scale, while statisticians more often rely on advanced mathematics, experimental design, and tools such as SAS, as summarized in this comparison of data science and statistics workflows.
What you usually get back is one of these:
- An experiment readout with a clear interpretation of results
- A formal analysis explaining whether an observed effect is credible
- A recommendation memo that includes assumptions, caveats, and decision guidance
- A survey or measurement plan that improves future data collection
This is what you want when rigor matters more than automation.
What a data scientist usually delivers
A data scientist's workflow spans more systems.
They often start upstream. Pull data from product logs, billing systems, CRM records, support tools, and warehouse tables. Clean and join it in Python, SQL, or notebooks. Engineer features. Train a model. Evaluate performance. Then push the result into a dashboard, API, or alerting flow that another team can use without asking for a fresh analysis every week.
Common outputs include:
- A churn scoring model used by customer success
- A ticket classification workflow for support operations
- A recommendation system inside the product
- A dashboard with automated issue ranking
- A scheduled pipeline that refreshes insights continuously
This is why data science often feels more connected to product execution. The deliverable isn't just a conclusion. It's a working mechanism.
What product managers should ask before kickoff
Before you staff a project, ask three questions:
- **Does this problem require causal confidence or operational speed?**If it's causal, lean statistical. If it's operational, lean data science.
- **Will the output be consumed once or reused repeatedly?**One-time strategic decisions often need formal inference. Ongoing workflows need systems.
- **Who acts on the result?**Executives often need a clear decision memo. Frontline teams need rankings, alerts, and integrations.
A useful way to pressure-test this distinction is to look outside product and revenue work. In people operations, for example, teams increasingly use predictive models to prioritize interventions and workforce planning. This overview of how HR leaders use predictive analytics is a good example of how the deliverable shifts from analysis alone to an operational decision tool.
If your PM expects a reusable workflow and receives a slide deck, the project isn't done. If leadership needs a defensible conclusion and receives a black-box score, the project answered the wrong question.
When Your SaaS Team Needs a Statistician
Some problems demand rigor first.
If your company is about to make a decision that changes pricing, onboarding, packaging, contract strategy, or customer communication at scale, you need someone who can design the analysis in a way that supports a defensible conclusion. In those moments, a statistician isn't optional. They reduce the risk of acting on noise.
High-stakes cases where inference matters
You need a statistician when the business asks questions like these:
- **Did this change cause the outcome?**Example: a revised onboarding sequence launched last month, and retention looks better. A statistician helps determine whether the sequence likely drove the difference or whether account mix, seasonality, or another factor explains it.
- **Is the experiment designed well enough to trust?**Example: the team wants to test a pricing page change. A statistician helps define the metric, randomization plan, and interpretation framework so the result doesn't collapse under scrutiny.
- **Is the sample good enough to generalize from?**Example: customer success runs a survey among power users and wants to treat the result as representative of the whole customer base. A statistician will push on sampling and bias before anyone overreacts.
What goes wrong without one
The most common failure isn't bad math. It's false confidence.
Teams see a directional result and label it proof. They compare before and after numbers without accounting for who entered the funnel, which customers were exposed, or whether the underlying groups were comparable. They read correlation as causation because the narrative feels right.
A statistician slows that down in the right way. They ask whether the model assumptions hold, whether the experiment can support the claim, and whether uncertainty is being communicated accurately.
When the cost of a wrong answer is high, rigor beats speed.
That's especially true in board-facing analyses, monetization decisions, and any roadmap choice that could redirect engineering time for a quarter.
When Your SaaS Team Needs a Data Scientist
Other problems don't stop at explanation. They need machinery.
If your team wants to predict account risk, route issues automatically, rank product problems by likely business impact, or turn large volumes of messy inputs into something usable every day, you need a data scientist. The job is not just to inspect data. It's to create a system that keeps producing value after the initial analysis.
Operational cases where scale matters
A data scientist is the right hire when your team needs to do things like:
- Score churn risk continuouslyCustomer success teams rarely need a one-time retention analysis. They need a living model that ingests fresh behavior, updates account-level risk, and helps reps focus on the right accounts. Teams building that kind of workflow often start from a framework like this guide to predictive churn modeling.
- Classify and prioritize unstructured feedbackSupport queues, call transcripts, and open-text feedback create volume faster than manual review can handle. A data scientist can build NLP-based pipelines that group issues, detect themes, and surface urgent patterns.
- Create product recommendations or next-best actionsIf you want to suggest relevant help content, identify accounts ready for expansion, or route feature requests to the right team, you need predictive and systems thinking.
What this role changes inside the company
A good data scientist doesn't just answer “what happened.” They shorten the distance between signal and action.
Instead of waiting for an analyst to rerun a query, a PM gets a dashboard that updates. Instead of reading every support ticket, an operations lead gets ranked issue clusters. Instead of manually reviewing usage patterns account by account, a CSM gets a prioritized list.
This role is strongest when the company already knows the business question and wants to execute against it repeatedly. That's why data science tends to shine in growth systems, lifecycle interventions, product intelligence, lead scoring, and recommendation workflows.
The key trade-off is that predictive usefulness doesn't automatically equal causal proof. A strong model can still be the wrong tool if leadership is trying to validate a strategic claim rather than run an operational process.
Building a Hybrid Team for Product Intelligence
The strongest SaaS teams don't treat data science vs. statistics as a winner-take-all decision.
They combine them. Statistics validates the signal. Data science operationalizes it. That pairing is often the most effective pattern for product intelligence work, where teams need both confidence and speed. A useful framing is that data science is judged by predictive and operational performance, while statistics is judged by inferential quality, and for AI product intelligence the best pattern is often hybrid: validate signals statistically, then use data-science pipelines to rank issues, automate routing, and refresh insights continuously, as described in this analysis of descriptive and benchmark-driven workflows.
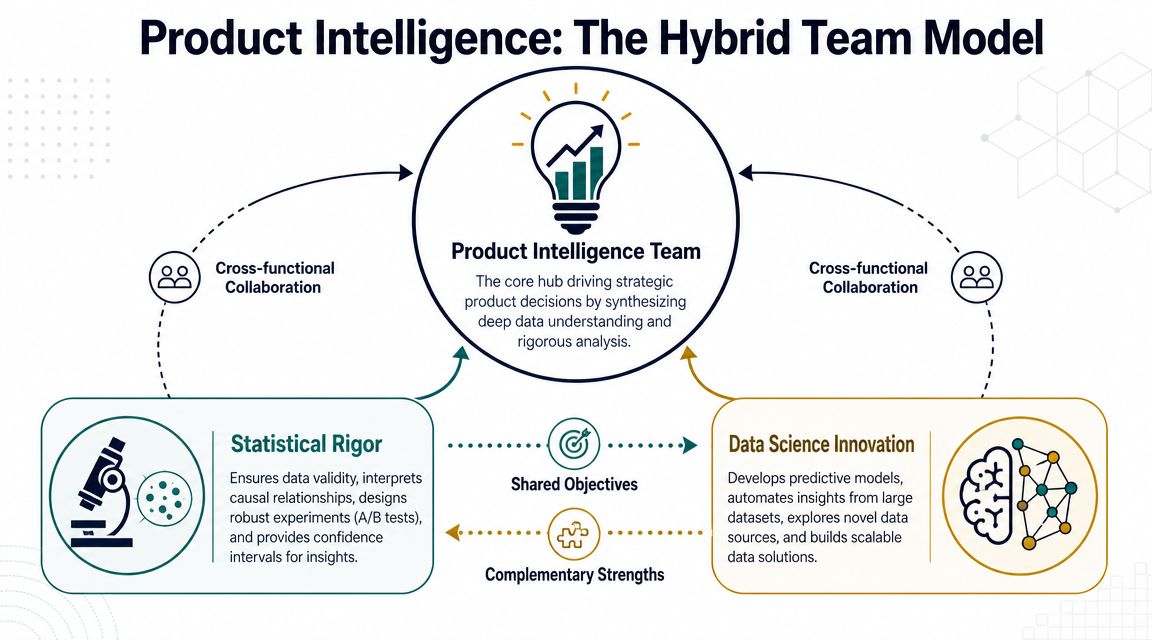
How the two roles complement each other
Here's what that looks like in practice:
- Statistics defines what's trustworthyIt helps the team confirm whether a churn indicator, expansion pattern, or product usage shift is likely meaningful.
- Data science makes it usableIt takes those validated signals and turns them into scoring, alerting, ranking, or workflow automation.
- Product leadership gets both confidence and actionabilityThe result isn't just an analysis nobody revisits. It's an operating layer the team can use weekly or daily.
A hybrid team doesn't ask whether one discipline replaces the other. It asks where each discipline creates leverage.
What to hire for
Most growing SaaS companies won't build large, neatly separated functions right away. They'll do better with T-shaped talent.
That means people with depth in one area and working fluency across the other. A strong data scientist should understand experiment design and uncertainty, even if they aren't a specialist statistician. A strong statistician should be comfortable enough with product data and tooling to collaborate on implementation.
If you're hiring for that blend, specialized marketplaces can help you find data science professionals with stronger applied experience than a generic title search usually reveals.
A practical team model for a SaaS company often looks like this:
- One statistics-heavy partner for experimentation, causal analysis, and measurement quality
- One data science-heavy partner for predictive systems, automation, and model deployment
- Product and operations leads who can translate business questions into the right analytical form
That structure keeps the team from making two classic mistakes. One is scaling bad assumptions. The other is producing good analysis that never reaches production.
If your team is trying to separate meaningful customer signals from support noise, product telemetry, and revenue risk, SigOS helps turn that mess into prioritized action. It gives product, growth, and customer teams a clearer view of which issues correlate with churn, expansion, and revenue impact so they can make faster decisions with more confidence.
Keep Reading
More insights from our blog



Ready to find your hidden revenue leaks?
Start analyzing your customer feedback and discover insights that drive revenue.
Start Free Trial →