Product Feedback Loop: A SaaS Playbook for Growth
Build a high-impact product feedback loop with this step-by-step SaaS playbook. Learn to collect, analyze, and prioritize feedback to drive revenue.

Most SaaS teams don't have a feedback problem. They have a decision problem.
The signals are everywhere. Zendesk tickets pile up. Sales drops feature requests into Slack. Customer success forwards renewal risks. Analytics shows friction, but nobody agrees on the cause. Product hears the loudest customers first, engineering gets vague tickets, and leadership asks why the roadmap still isn't moving churn or expansion.
A working product feedback loop fixes that, but not in the way commonly assumed. The goal isn't to collect more comments. The goal is to connect customer input to business outcomes, then ship the changes most likely to protect revenue and create growth.
Why Your Product Feedback Loop Is Broken and How to Fix It
The usual failure mode looks familiar. A product manager triages support issues on Monday, joins sales calls on Tuesday, reads survey comments on Wednesday, and by Friday still can't answer a basic question: which problem matters most right now?
That happens when feedback is treated as an inbox instead of an operating system. Teams collect plenty of input, but they don't run a disciplined cycle to collect, analyze, implement, and follow up. Modern product practice moved in that direction for a reason. Salesforce's State of the Connected Customer found that 65% of customers expect organizations to adapt to their changing needs, a shift highlighted in Dovetail's overview of the product feedback loop. If your product process can't keep adapting, customers feel it before your dashboard does.
What's actually broken
The issue usually isn't a lack of listening. It's one of these:
- Channels are fragmented: Feedback lives in Intercom, Gong, Jira comments, Slack threads, and CRM notes.
- Volume gets mistaken for priority: A noisy cluster of requests outranks a quieter issue tied to churn.
- Requests are taken at face value: Teams build what customers asked for, not the underlying job they were trying to complete.
- Follow-up never happens: Users submit feedback and hear nothing back, so future signal quality drops.
Practical rule: If your team can't explain why a roadmap item matters in terms of retention, expansion, or customer risk, it probably came from noise, not signal.
What a fix looks like
A healthy product feedback loop is continuous, not campaign-based. It doesn't ask, “What did customers say this quarter?” It asks, “What pattern is recurring across accounts, what behavior does it correlate with, and what happens to revenue if we ignore it?”
That changes the operating model:
- Centralize every signal
- Translate raw feedback into themes
- Connect themes to user behavior and account context
- Prioritize by business impact, not request count
- Respond after a decision is made, whether the answer is yes or no
If you're rebuilding intake, the quality of your prompts matters more than is generally understood. Asking sharper questions at the point of interaction improves everything downstream. A practical starting point is this guide on how to ask for customer feedback.
The strongest product teams don't run a democratic roadmap. They run a weighted one.
Designing Your Feedback Collection Engine
A revenue-aware product feedback loop starts with coverage. If collection is narrow, analysis will be wrong no matter how advanced your scoring model looks later.
The first design choice is simple. Separate active feedback from passive feedback, then route both into one system of record.
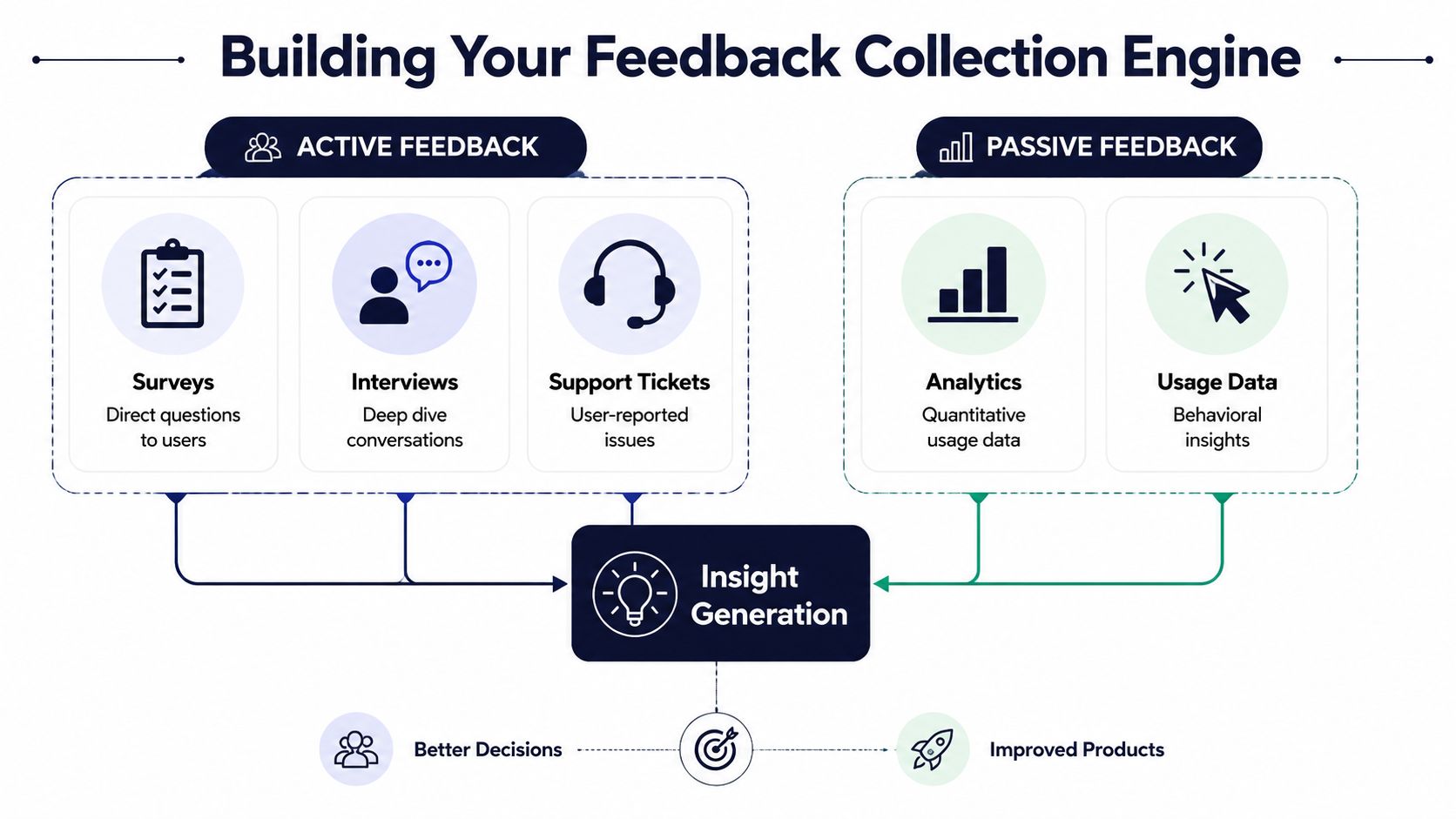
Active signals and passive signals
LaunchDarkly's guidance captures the split well. Usage metrics and performance data show what is happening, while open-ended comments, interviews, and tickets explain why it is happening, and it also recommends in-app microsurveys of 1–3 questions at key moments to improve response quality, as covered in its product feedback loop guide.
That distinction matters operationally.
Active feedback sources
These are direct expressions from users and prospects:
- Support tickets: Zendesk and Intercom reveal repeated friction in live workflows.
- Customer interviews: Useful for unpacking motivation, confusion, and workarounds.
- CS and sales call notes: Good for hearing objections, renewal risk, and expansion blockers.
- Surveys and forms: Best when they're short and tied to a moment in the journey.
If your team needs a faster way to stand up structured intake without writing every prompt from scratch, curated online feedback form templates can help standardize collection across product, support, and customer success.
Passive feedback sources
These don't require the user to say anything:
- Product analytics: Feature usage, drop-offs, repeated errors, incomplete workflows.
- Session behavior: Where users hesitate, retry, abandon, or route around intended paths.
- Performance telemetry: Latency, failure patterns, and reliability issues that users experience before they report them.
- Cancellation and downgrade behavior: Often the clearest sign that “silent” feedback already exists.
Build one ingestion path
Don't let each team invent its own storage layer. Pipe feedback into one shared repository, whether that's a dedicated feedback platform, a data warehouse-backed workflow, or a tightly structured Airtable or Notion setup at smaller scale.
The fields matter more than the tool at first. Every record should include:
- Source channel
- Account or user segment
- Product area
- Feedback type
- Original verbatim
- Observed behavior linked to the issue
- Owner for triage
The point of collection isn't completeness. It's usable coverage across segments, lifecycle stages, and product surfaces.
A dedicated customer feedback analysis tool becomes more valuable once intake is standardized, because analysis breaks down fast when the source data is inconsistent.
Use microsurveys surgically
Organizations often over-survey and under-target. Short in-app prompts work when they appear at high-intent moments, such as after onboarding, after repeated use of a feature, or right before cancellation. Keep the question count low, ask about the immediate experience, and leave room for one open text response when context matters.
Broad prompts like “Any feedback?” produce broad, low-value answers. Contextual prompts tied to an action produce insight you can route into the roadmap.
From Raw Feedback to Actionable Signals
Collection creates inventory. Analysis creates judgment.
A common pitfall is when many product feedback loops fail subtly. Teams gather a large pile of comments, label a few broad themes, then react to whichever cluster feels urgent. That's how anecdote turns into roadmap.

Avoid channel bias before you score anything
One of the most damaging mistakes is trusting a single channel too much. Formbricks puts it plainly: “single-channel feedback creates survivorship bias”, and it recommends combining in-app surveys, interviews, support tickets, public reviews or forums, and usage analytics to capture both explicit opinions and observed behavior, as noted in its product feedback loop write-up.
That warning is more practical than academic.
If you only listen to support tickets, you'll overweight customers who complain. If you only listen to interviews, you'll overweight customers willing to talk. If you only watch analytics, you'll see friction but miss intent. Good analysis starts by accepting that every channel lies in its own way.
A workable triage model
The fastest way to clean raw feedback is to tag for retrieval, not for perfection. Teams get stuck when they create taxonomies that look elegant and never get used.
Use tags that answer operational questions:
| Field | Why it matters |
|---|---|
| Theme | Groups recurring problems such as onboarding, billing, reporting, permissions |
| Segment | Separates SMB from enterprise, new users from mature accounts, trial from paid |
| Severity | Distinguishes blockers from annoyances |
| Intent | Marks bug, feature gap, usability issue, performance problem, or praise |
| Evidence type | Shows whether the issue is stated, observed, or both |
Once records are tagged, look for intersections rather than totals. A theme becomes meaningful when it shows up across channels and appears next to relevant behavior.
For example, “report exports are confusing” is still vague. It becomes actionable when you can say:
- enterprise admins mention it in calls,
- support tickets repeat the same workflow failure,
- usage data shows abandonment in the export flow,
- and downgrading accounts touched that workflow before reducing usage.
Turn complaints into testable product work
Raw comments rarely belong in Jira as-is. Product has to translate them.
Here's the shift:
- “Your dashboard is a mess” becomes a navigation hypothesis.
- “I can't trust this data” becomes a reporting accuracy or labeling issue.
- “We need permissions” becomes a scoped access-control requirement tied to a user role.
That translation work is easier when teams understand what qualitative data analysis requires. The point isn't sentiment scoring for its own sake. It's pattern extraction with enough structure that engineering, design, and leadership can act on it.
A recurring pattern with weak revenue linkage should stay below a smaller pattern tied to churn risk in a valuable segment.
That's where analysis stops being descriptive and starts becoming commercial.
Prioritizing What Moves the Needle
Most prioritization frameworks are useful. Few are sufficient.
ICE, RICE, and similar models help teams compare effort and expected upside. They're good at creating order. They're weaker at answering the question executives care about most: what should we build first if the goal is to reduce churn and expand revenue?
Volume alone won't answer that. Neither will internal enthusiasm.
Why common frameworks fall short
The blind spot is predictable. Traditional models often treat all requests as roughly equal inputs, then score for reach, confidence, and effort. That works for growth experiments and broad roadmap sorting. It works less well when ten users in a strategic segment matter more than a hundred users outside your core market.
A product feedback loop for SaaS needs a second layer. After you score feasibility and customer pain, you should weight the issue by business exposure.
Here's a practical comparison.
Comparison of Prioritization Frameworks
| Framework | Key Variables | Best For | Potential Blind Spot |
|---|---|---|---|
| ICE | Impact, confidence, ease | Quick internal ranking | Doesn't capture account value or churn exposure well |
| RICE | Reach, impact, confidence, effort | Growth experiments and broad planning | Reach can overweight low-value users |
| Theme voting | Request count by topic | Spotting broad demand | Loud customers distort demand |
| Strategic fit | Company goals, roadmap alignment | Long-range direction | Can ignore urgent customer pain |
| Revenue-impact model | Account value, churn risk, expansion potential, frequency, implementation effort | SaaS roadmap decisions tied to retention and growth | Requires better data hygiene and cross-team coordination |
Build a revenue-impact score
You don't need a complicated formula to get better decisions. You need consistent inputs.
A practical model usually includes:
- Customer value: Is the issue concentrated in accounts that matter commercially?
- Risk level: Is this problem showing up near downgrades, low adoption, or renewal pressure?
- Expansion relevance: Would fixing it unblock a bigger rollout, seat growth, or plan upgrade?
- Pattern strength: Is it recurring across channels and segments, or isolated?
- Delivery cost: How much design, engineering, and support effort will it take?
This changes roadmap conversations fast. A low-volume request from accounts evaluating a larger deployment may beat a high-volume feature idea from casual users. A workflow bug tied to cancellation behavior should outrank a commonly requested polish improvement.
Decision heuristic: Don't ask only “how many asked for this?” Ask “what revenue are we defending or unlocking if we solve it?”
Make the score defensible
The scoring process needs shared language with sales, success, and finance. Otherwise, product will still get dragged back into opinion battles.
A good review rhythm looks like this:
- Product validates the pattern and defines the likely root problem.
- Customer success adds account context and renewal risk.
- Sales flags whether the issue affects expansion or deal progression.
- Engineering sizes the work realistically.
- Leadership reviews trade-offs against strategic bets already in motion.
If your team needs a simple refresher on ranking work at the operational level, WeekBlast's guide to task management is a useful companion to the more strategic model above.
The main shift is cultural. Stop treating every feature request as a vote. Start treating feedback as evidence with uneven business weight.
Integrating Feedback into Your Workflow
A feedback loop only matters if engineering can use it without extra detective work.
The handoff fails when product creates tickets that say things like “customers are confused” or “sales needs this for enterprise.” Those aren't implementable work items. They're placeholders for a conversation nobody scheduled.
What a context-rich ticket includes
By the time feedback reaches Jira, Linear, or GitHub, it should already be distilled and attached to evidence. The best tickets carry enough context that engineering can challenge the solution, not the existence of the problem.
A strong ticket usually contains:
- Problem statement: One sentence describing the user friction.
- Affected segment: Which users or account types are seeing it.
- Supporting evidence: Relevant verbatims, ticket clusters, call excerpts, and observed product behavior.
- Business context: Why this issue matters commercially.
- Success criteria: What behavior should change after release.
- Release notes target: Who should be informed if it ships.
Remove manual hops
Manual copy-paste work kills consistency. Connect your feedback system to the tools where execution happens. That often means syncing from Zendesk, Intercom, Gong notes, product analytics, and survey tools into one analysis layer, then pushing vetted issues into Jira, Linear, or GitHub.
This is also where tooling choices matter. Some teams use warehouse workflows and internal scripts. Others use specialized platforms. For example, SigOS ingests support tickets, chat transcripts, sales calls, and usage metrics, then routes issues into tools like Jira and Linear with revenue-impact context. It's one way to reduce the gap between signal detection and execution without asking product managers to manually stitch everything together.
Design for developer clarity
Engineers don't need more tickets. They need better ones.
If you're cleaning up this handoff, it helps to think about the broader system that shapes build speed and team frustration. This guide on how to improve developer experience is useful because it frames the issue correctly: unclear inputs create downstream waste.
A simple workflow that works well in practice:
| Step | Owner | Output |
|---|---|---|
| Triage | Product or ops | Tagged issue cluster |
| Validation | Product plus CS or data | Confirmed recurring pattern |
| Prioritization | Product leadership | Ranked issue with business rationale |
| Ticket creation | Product | Engineering-ready spec |
| Release feedback | Product marketing or CS | User follow-up and adoption monitoring |
When this system works, feedback stops being an interruption and becomes part of delivery infrastructure.
Closing the Loop and Measuring Success
Shipping the fix isn't the end of the product feedback loop. It's the point where trust is either reinforced or lost.
Users notice when they took the time to explain a problem and the company stayed silent. They also notice when a team responds clearly, even if the answer is that the request wasn't prioritized. Closing the loop is operational discipline, not a nice touch.

Respond after every decision
Modern guidance increasingly treats loop closure as something measurable. Teams should track the share of feedback that receives a response, whether the message is “we built this” or “we decided not to.” That keeps the system operational instead of symbolic.
The response method should match the account context:
- High-value accounts: Personal outreach from CSM, PM, or account executive.
- Broader product changes: Changelog entries, in-app notices, or lifecycle emails.
- Rejected requests: Brief explanation tied to product direction or trade-offs.
Users don't require every request to be approved. They do expect evidence that someone evaluated it seriously.
Measure process health and business impact
Tendril's guidance is useful here because it sets realistic expectations. ROI from feedback-loop investments often becomes visible only after 6-12 months, and teams should track process metrics such as response time and completion rate along with business outcomes such as retention and revenue impact. It also warns against failing to define success metrics before implementation, as explained in its article on building customer feedback loops that drive product roadmaps.
That means your scorecard should include both operating metrics and outcome metrics.
Process metrics
- Response time: How quickly feedback is acknowledged or dispositioned
- Completion rate: How much feedback receives a clear resolution state
- Cycle time: How long it takes for validated issues to move into delivery
Business metrics
- Retention movement: Whether targeted segments stabilize after a fix
- Expansion signals: Whether blocked accounts adopt more after the improvement
- Revenue relevance: Whether roadmap work is increasingly tied to commercial outcomes
The most mature teams measure the loop itself, not just the product changes it produces. That's how you prove that better listening isn't overhead. It's part of how the business grows.
If your team is sitting on feedback spread across support, sales, and product data, SigOS can help turn that mess into prioritized signals tied to churn, expansion, and revenue impact. It's built for teams that want their product feedback loop to drive roadmap decisions with commercial context, not just request volume.



Ready to find your hidden revenue leaks?
Start analyzing your customer feedback and discover insights that drive revenue.
Start Free Trial →