What Is Reverse ETL: Data to Action for 2026
Discover what is reverse etl: move data from warehouses to business tools. Empower teams to act on insights instantly in 2026.

Reverse ETL pushes already transformed data from your warehouse back into operational tools like CRMs and marketing platforms, and that's why it matters. Market commentary projects a 26% CAGR through 2030 and a market size of $48.3 billion by 2030, with large enterprises holding over 64% of adopters, because teams increasingly need warehouse data to show up where work happens.
You're probably in one of these situations right now. Your analysts have built solid models in Snowflake, BigQuery, or Databricks. Product usage is mapped. Support trends are tagged. Customer health is visible in a dashboard. But the sales team still asks for CSV exports, marketing still builds audiences from partial data, and support reps still work tickets without the customer context your warehouse already has.
That's the gap Reverse ETL closes.
If you've searched for what is Reverse ETL, most answers stop at the definition. They tell you data moves out of the warehouse and into business tools. That's true, but it misses the key buyer question. What problem does this solve that your current stack doesn't already solve?
The short answer is this: it solves the last mile problem between analysis and action. Your warehouse may already be your source of truth. Reverse ETL makes it your source of execution, too.
The Data Is In But Action Is Out
It's Monday morning. Your product manager is reviewing feature adoption in a dashboard. Your support lead can see which accounts filed repeated tickets last week. Your lifecycle marketer knows which users reached activation but never converted. The insight exists. The teams who need to act on it still do not have it inside the tools they use all day.
That is the actual problem.
In many SaaS companies, the warehouse already holds a clean, modeled view of the customer. Analysts have done the hard work. They joined product events, billing history, CRM activity, and support data. They created useful fields such as account health, expansion likelihood, feature adoption, and churn risk. Yet the sales rep still opens Salesforce without that context. The marketer still builds audiences in HubSpot from partial data. The support agent still answers a ticket in Zendesk without seeing the warning signs the warehouse already captured.
The issue is not analysis quality. It is the last mile between knowing and doing.
A dashboard works like a control tower. It gives visibility. Frontline teams, though, work more like pilots in the cockpit. They need the right signal in front of them while they are making a decision, not in a separate system they have to remember to check.
Where the bottleneck shows up
- Sales teams lose context: Reps live in the CRM, so warehouse insights often stay out of the conversation unless someone exports and syncs them by hand.
- Marketing teams work with stale segments: Campaign tools usually reflect the data already inside them, not the richer lifecycle and product models built in the warehouse.
- Support teams react after the fact: Risk scores and usage changes may exist in reporting, but they are absent from the ticket workflow where prioritization happens.
Data creates business value when it appears inside the system where a team is already taking action.
This is why reverse ETL gets attention from operating teams, not just data teams. It addresses a gap your current stack often leaves open. Warehouses are good at centralizing and modeling data. BI tools are good at helping people inspect it. Neither one, on its own, updates the CRM record, refreshes the campaign audience, or adds customer context to a support queue.
For teams thinking about growth execution more broadly, The AI CMO's insights on growth frame the same issue from the marketing side. Intelligence only changes outcomes when it shows up where decisions are made.
The last mile problem in plain English
Your warehouse works like a library full of accurate customer knowledge. A rep on a live sales call does not need a library. They need one useful fact on the account page before they ask the next question.
That is the gap reverse ETL closes. It turns modeled warehouse data into operational context that product, support, sales, and growth teams can use.
ETL ELT and Reverse ETL Explained
Most confusion starts because ETL, ELT, and Reverse ETL sound like variants of the same thing. They're related, but they solve different jobs.
A kitchen analogy makes this easier.
ETL is like bringing ingredients into the restaurant, prepping them, and then putting them into the kitchen system. ELT is like bringing ingredients into the kitchen first, then preparing them there. Reverse ETL is the waiter carrying the finished dish out to the table where someone can eat it.
That last step matters. A plated meal sitting in the kitchen is complete, but it still hasn't delivered value to the customer.
The simplest definition
dbt describes Reverse ETL as the outbound half of the modern data stack. It pushes already transformed warehouse data back into operational tools like CRMs and marketing platforms, so analytics become actionable inside a team's normal workflow instead of requiring another login to a BI tool.
The core difference
| Process | Data Flow Direction | Primary Purpose | Example |
|---|---|---|---|
| ETL | Operational systems to warehouse | Prepare data before analysis storage | Pull app and billing data, transform it, load to a warehouse |
| ELT | Operational systems to warehouse, then transform in warehouse | Centralize first, model later | Load raw SaaS data into Snowflake, then model with dbt |
| Reverse ETL | Warehouse to operational tools | Put modeled data into business workflows | Sync account health score from warehouse to Salesforce |
Why people mix them up
They all move data. But the direction and purpose differ.
- ETL and ELT help analysts and data teams answer questions.
- Reverse ETL helps sales, support, and growth teams act on the answers.
Practical rule: If the destination is a warehouse, you're organizing data for analysis. If the destination is Salesforce, HubSpot, Zendesk, Intercom, or an ad platform, you're probably operationalizing analysis.
A useful way to think about it
If ETL and ELT create a reliable record of what happened, Reverse ETL helps your business respond to it.
For example, suppose your warehouse model identifies accounts with strong product adoption but no recent sales touch. ETL and ELT got the raw ingredients into shape. Reverse ETL sends the finished signal into the CRM so the sales team can see it on the account and prioritize outreach.
That's also why the term often overlaps with data activation and operational analytics. The point isn't the pipe. The point is making data useful in daily work.
The Reverse ETL Architecture and Data Flow
Reverse ETL sounds abstract until you trace the path the data moves. In practice, the architecture is straightforward. A warehouse acts as the source of truth. A reverse ETL tool reads a modeled table or query. Then it syncs selected fields into a business application through that tool's API.
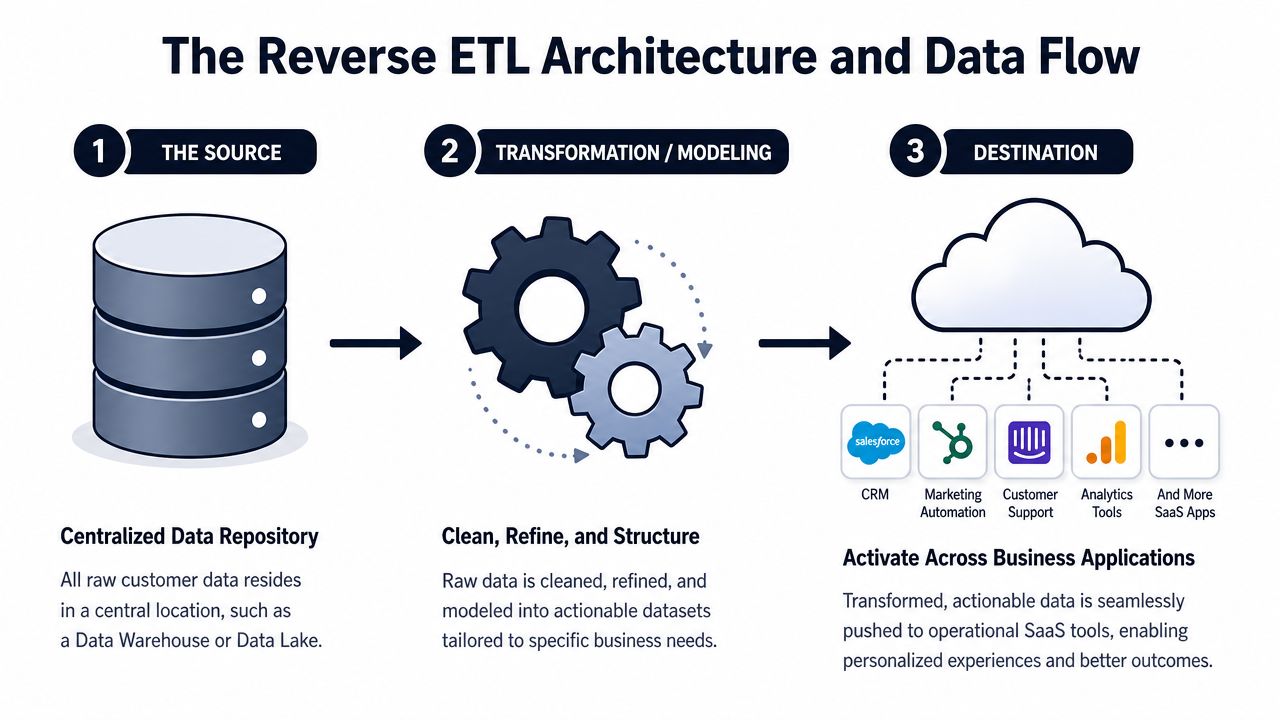
If you want a broader visual reference for how this fits into a modern stack, this data architecture diagram guide is a helpful companion because it shows how warehouses, transformation layers, and downstream tools connect at a system level.
Stage one is the source
The process starts in your warehouse or lakehouse. This is usually where data from product analytics, billing systems, support tools, and go-to-market platforms has already been centralized and modeled.
What matters here isn't raw data. It's the modeled output.
That might be:
- A customer health model: one row per account with risk indicators
- A feature adoption model: one row per user or account with activation milestones
- A lead scoring model: one row per prospect with product and commercial signals combined
Stage two is the sync logic
The reverse ETL layer selects the records and fields to send. It may filter, reshape, rename, or map them so the destination system can accept them properly.
For example, your warehouse may use account_id, while Salesforce expects a specific external ID field. Your model may calculate a churn reason as a text label, while Zendesk may need that value in a custom field. In these situations, field mapping matters.
Improvado's explanation of reverse ETL delivery captures the key point well. The pipeline extracts from a warehouse and loads into SaaS destinations on a schedule, which can support workflows like segmentation, routing, or risk scoring without manual exports. The measure of success is whether the data arrives fast enough to influence the business process.
Stage three is the destination
The destination is the tool where somebody works. That might be:
- Salesforce or HubSpot for sales and customer success
- Marketo or Braze for lifecycle marketing
- Zendesk or Intercom for support operations
- Ad platforms for audience activation
Once the sync lands, those systems can use warehouse-derived fields as if they were native.
The data doesn't need to move everywhere. It needs to move to the place where a decision happens.
What changes after the sync
Before Reverse ETL, the warehouse contains the answer. After Reverse ETL, the business tool can use the answer.
That can mean a CRM record gets a fresh health score, a support ticket gets a risk flag, or a marketing platform gets an audience attribute it can use for suppression or personalization. The mechanics aren't magical. They're just structured enough to make action repeatable.
Practical Use Cases That Drive Growth and Retention
A familiar pattern shows up in growing SaaS companies. The warehouse already contains answers about who is likely to expand, who is drifting toward churn, and which accounts are getting real value. Yet the teams who could act on those answers are still working from partial context inside the tools they use every day.

That is the last mile problem.
Reverse ETL closes it by taking a signal that already exists in the warehouse and placing it inside the CRM, marketing platform, or support system where a person can act on it right away. For a product manager, that means fewer good insights dying in dashboards. For revenue and support teams, it means better timing, better context, and fewer manual workarounds.
Product teams stop guessing which accounts are ready
Product teams often spot revenue signals first. Usage patterns can show that an account has reached activation, adopted a high-value feature, or invited enough teammates to suggest expansion potential.
Without Reverse ETL, a product manager shares that insight through a report, a Slack message, or a spreadsheet export. The sales or success team still has to translate that insight into outreach. By the time that happens, the window may have narrowed.
With Reverse ETL, the warehouse-modelled signal becomes a field in Salesforce or HubSpot. The account owner can filter by product-qualified accounts, trigger a task, or prioritize outreach based on actual behavior instead of guesswork.
The practical change is simple. Product insight becomes operational.
- Before: The PM asks for a one-off list of accounts using Feature X heavily.
- After: The CRM already shows which accounts crossed the adoption threshold and who should follow up.
Growth teams can personalize from warehouse truth
Marketing tools are good at execution. They are not always the best place to define customer truth.
The warehouse usually has the fuller picture because it combines product usage, billing status, plan history, support activity, and lifecycle stage in one model. Reverse ETL takes those modeled traits and syncs them into Braze, Marketo, or HubSpot so campaign logic uses the same definitions the data team trusts.
That changes the quality of targeting in a very practical way. A growth team can suppress current customers from acquisition campaigns, send upgrade prompts after meaningful usage milestones, or tailor onboarding based on actual behavior rather than a static signup form.
Examples include:
- Lifecycle stage derived from product behavior
- Suppression of active customers from paid acquisition flows
- Expansion messaging tied to real usage milestones
- Reactivation campaigns based on declining engagement
If your team is still asking marketers to pull CSVs from dashboards, it is usually a sign that the stack supports analysis better than action. That gap is one reason companies invest in self-serve analytics for business teams, then extend it with Reverse ETL so insights do not stop at reporting.
Teams evaluating outbound workflows run into a similar issue in sales tooling. A comparison like Orbbit vs Apollo for sales teams is useful for choosing where reps work, but the larger question is whether those tools receive the right warehouse-derived signals in the first place.
Support teams get context before the customer leaves
Support and success teams often see the symptoms of churn before anyone else. They hear the complaints, notice repeated ticket types, and recognize when an account's tone shifts from confused to frustrated.
What they often lack is the modeled context sitting in the warehouse.
A data team may identify that usage drops after a certain onboarding issue, or that repeated billing tickets often appear before downgrade requests. Reverse ETL can sync those indicators into Zendesk or Intercom so the agent handling the case sees risk context while the conversation is still active.
That matters because timing matters. A health score in a dashboard helps with reporting. A health score on the account record during an escalation helps the team intervene.
- Before: An agent resolves the ticket without knowing the account also shows declining usage and repeated friction.
- After: The ticket view includes churn risk, recent product activity, and account tier so the response can match the situation.
Here's a quick explainer if you want to see a visual walkthrough before mapping your own use cases:
The pattern behind all three examples
The core pattern is the same across product, growth, and support. The signal already existed. Reverse ETL changed whether the right team could use it in time.
| Team | Before Reverse ETL | After Reverse ETL |
|---|---|---|
| Product | Insights stay in dashboards or analyst queues | Product-qualified segments appear in CRM and planning tools |
| Growth | Campaign tools use partial or outdated attributes | Messaging uses warehouse-modeled traits |
| Support | Risk context is manual, delayed, or missing | Agents see risk indicators inside live workflows |
The business value comes from faster action, not from data movement by itself. Reverse ETL turns analysis into something a person can use during a sales call, campaign launch, or support escalation. That is how it closes the last mile between knowing and doing.
Operationalizing Insights with a Product Intelligence Platform
Reverse ETL gets more interesting when the source data isn't just transactional or behavioral, but interpretive. That includes signals pulled from support conversations, sales calls, feedback trends, and usage patterns.
A product intelligence platform can surface patterns that wouldn't exist as a native field in a CRM. For example, support conversations may reveal repeated invoice confusion, onboarding friction, or feature requests linked to expansion potential. Those insights are useful in a dashboard, but they become operational only when they're pushed into the systems where account teams, support leads, or product squads work.
What that looks like in practice
A common flow looks like this:
- Insight generation in the intelligence layerSupport text, call notes, and usage patterns are analyzed and grouped into business-relevant themes.
- Modeling in the warehouseThe team creates fields such as
churn_risk_reason,expansion_signal, orfeature_request_priority. - Activation through Reverse ETLThose modeled fields are synced into Salesforce, Zendesk, Jira, or Linear.
The key idea is simple. The warehouse becomes the place where intelligence is standardized. Reverse ETL becomes the way that intelligence reaches people in operational systems.
Why this matters to product managers
A product manager usually doesn't want another dashboard to babysit. They want prioritization signals embedded in the tools that already control execution.
For example, if revenue-linked feature demand is written into Jira or Linear, backlog conversations get sharper. If churn reasons are synced into Salesforce, customer success can intervene with context. If a sales team is comparing workflow options, practical buying comparisons like Orbbit vs Apollo for sales teams help illustrate the same principle from another angle: operational tools are only as effective as the quality of context inside them.
A related idea shows up in strong self-serve analytics practices. Self-service works best when people don't have to translate analytics manually from one system into another. Reverse ETL is one of the mechanisms that makes that possible.
The most useful insight isn't the one your analyst can explain. It's the one your team can act on without asking for help.
Key Implementation and Operational Considerations
Buying or building Reverse ETL is usually the easy part of the conversation. Running it well is harder.
The operational questions tend to look less exciting than the demo, but they determine whether the system helps or creates noise.
Start with freshness, not features
Rivery's guidance on reverse ETL tradeoffs highlights a point that many explainers skip. The critical operational decision is identifying the minimum data freshness and reliability needed for a workflow to be valuable, because revenue, support, and product teams don't all tolerate delay or error the same way.
That means you shouldn't ask, “Can this sync in near real time?” first.
Ask:
- What decision depends on this field?
- How stale can it be before the workflow breaks down?
- Who notices first if the sync fails?
A support routing flag may need to land quickly. A weekly lifecycle audience may not.
Governance is not optional
Once warehouse data starts flowing into business tools, ownership gets blurry unless you define it early.
Consider these questions:
- Who owns the model? The data team, RevOps, product ops, or marketing ops?
- Who approves field definitions? “Health score” sounds clear until three teams use different logic.
- Who monitors drift or breakage? Destination schemas change. APIs change. People rename fields in Salesforce.
If you already wrestle with model trust, it's worth tightening your approach to data quality issues before operationalizing fields downstream. Reverse ETL amplifies whatever quality level already exists upstream. Clean logic becomes more useful. Messy logic becomes more visible.
Build vs buy depends on complexity
A custom integration can work when you have one destination and a narrow use case. It gets harder when teams want many destinations, field mapping, retries, alerting, deduplication, scheduling, and change management.
A managed tool is often the practical choice when:
| Situation | Better fit |
|---|---|
| One narrow sync, strong internal engineering capacity | Build |
| Many business systems, changing schemas, multiple owners | Buy |
| Strict governance and audit needs across teams | Usually buy |
| Experimental pilot with one workflow | Either can work |
Watch the boring failure modes
The glamorous story is activation. The true story is maintenance.
Reliability matters more than novelty. A broken health score in Salesforce is worse than no health score at all.
Common failure points include field mismatches, duplicate record updates, destination-side validation changes, and silent sync failures that nobody notices until a campaign or workflow underperforms. The strongest implementations treat Reverse ETL as production infrastructure, not as a convenience script.
Is Reverse ETL the Missing Piece in Your Data Stack?
If your warehouse already holds the best version of customer truth, the next question isn't whether that's useful. It's whether that truth is reaching the people who need it in time to change an outcome.
Fivetran's framing of the buyer question is the right one. For many businesses, the issue isn't “what is Reverse ETL?” but what problem does it solve that the current stack does not. It becomes necessary when the gap between warehouse-modeled data and the need for that data in operational tools begins to slow business execution.
A quick self-check
Reverse ETL is worth serious attention if these sound familiar:
- Your teams keep asking for CSV exports: That usually means useful data exists, but not in the right place.
- Business users trust the CRM more than the BI layer: Even when the warehouse contains richer logic.
- Insights arrive after the moment to act: A risk score found tomorrow may not help the support rep working the ticket today.
- Different teams recreate the same segment manually: That's a sign the warehouse knows something your operational tools don't.
A lot of integration pain shows up after activation, not before it. If you're evaluating how operational systems should connect cleanly, this guide to avoiding integration pitfalls is a useful read because it focuses on the handoff issues that often undermine otherwise good tooling choices.
Reverse ETL isn't magic. It won't fix weak modeling, unclear ownership, or poor system design. But when your warehouse has become the source of truth and your business still runs on disconnected tools, it can be the missing layer that turns analysis into execution.
If your team is sitting on rich product, support, and revenue signals but struggling to operationalize them, SigOS can help surface the patterns that matter and make them easier to act on. It gives product and growth teams a clearer view of which issues, requests, and behaviors are tied to churn risk, expansion, and revenue impact so the insights in your data don't stay trapped in dashboards.
Keep Reading
More insights from our blog



Ready to find your hidden revenue leaks?
Start analyzing your customer feedback and discover insights that drive revenue.
Start Free Trial →